
I am a fourth-year Ph.D. candidate at the Department of Computer Science at University of Maryland, College Park, CLIP Lab. I am fortunate to be advised by Jordan Boyd-Graber. My current research lies in Human-Centered AI, Multimodal Models, Post-Training and Evaluation.
Current Research Focus
My research aims to develop AI systems and better evaluations that align closely with human needs. In the text-only domain, I aim to develop interactive systems that help humans explore and understand abstract concepts given large amounts of data and improve the robustness of current automatic evaluation metrics. In the multimodal domain, I aim to evaluate and post-train multimodal models—including visual grounding, hallucination mitigation, video generation and reasoning.
-
Multimodality: Evaluating and improving multimodal models, including question answering, hallucination, video generation, and reasoning.
-
Evaluation: Improving trustworthiness and robustness of current evaluation metrics.
-
Human-Centered AI: Creating interactive systems and evaluation frameworks to assess AI reliability.
Reviewer Experience
I have served as a reviewer for ACL, EMNLP, NAACL, ICLR, Nips, CVPR, IEEE, ACM.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 University of Maryland, College ParkDepartment of Computer Science
University of Maryland, College ParkDepartment of Computer Science
Ph.D. StudentSep. 2022 - present -
University of Maryland, College ParkB.S. in Computer Science and Mathematics (Honors)Sep. 2018 - May. 2022
Honors & Awards
-
Lambda Lab Research Compute Grant2025
-
NIST Award Fellowship2023-2025
News
Selected Publications (view all )

First Frame Is the Place to Go for Video Content Customization
Jingxi Chen*, Zongxia Li*, Zhichao Liu, Guangyao Shi, Xiyang Wu, Fuxiao Liu, Cornelia Fermüller, Brandon Y. Feng, Yiannis Aloimonos (* equal contribution)
Preprint 2025
What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
First Frame Is the Place to Go for Video Content Customization
Jingxi Chen*, Zongxia Li*, Zhichao Liu, Guangyao Shi, Xiyang Wu, Fuxiao Liu, Cornelia Fermüller, Brandon Y. Feng, Yiannis Aloimonos (* equal contribution)
Preprint 2025
What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
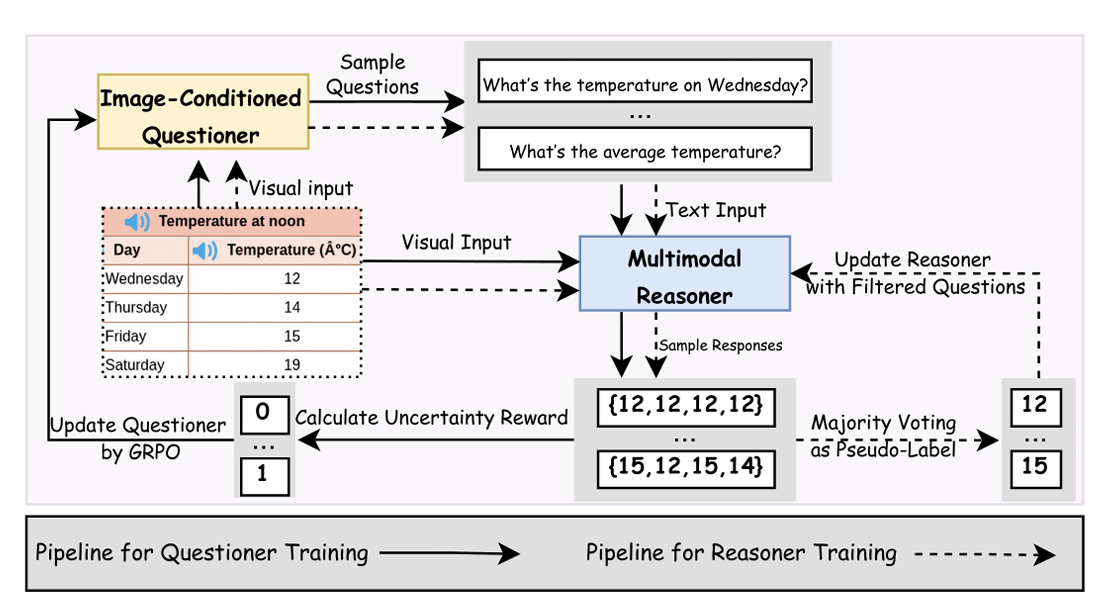
VisPlay: Self-Evolving Vision-Language Models from Images
Yicheng He*, Chengsong Huang*, Zongxia Li*, Jiaxin Huang, Yonghui Yang (* equal contribution)
Preprint 2025
Reinforcement learning (RL) provides a principled framework for improving Vision-Language Models (VLMs) on complex reasoning tasks. However, existing RL approaches often rely on human-annotated labels or task-specific heuristics to define verifiable rewards, both of which are costly and difficult to scale. We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning abilities using large amounts of unlabeled image data. Starting from a single base VLM, VisPlay assigns the model into two interacting roles: an Image-Conditioned Questioner that formulates challenging yet answerable visual questions, and a Multimodal Reasoner that generates silver responses. These roles are jointly trained with Group Relative Policy Optimization (GRPO), which incorporates diversity and difficulty rewards to balance the complexity of generated questions with the quality of the silver answers. VisPlay scales efficiently across two model families. When trained on Qwen2.5-VL and MiMo-VL, VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks, including MM-Vet and MMMU, demonstrating a scalable path toward self-evolving multimodal intelligence.
VisPlay: Self-Evolving Vision-Language Models from Images
Yicheng He*, Chengsong Huang*, Zongxia Li*, Jiaxin Huang, Yonghui Yang (* equal contribution)
Preprint 2025
Reinforcement learning (RL) provides a principled framework for improving Vision-Language Models (VLMs) on complex reasoning tasks. However, existing RL approaches often rely on human-annotated labels or task-specific heuristics to define verifiable rewards, both of which are costly and difficult to scale. We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning abilities using large amounts of unlabeled image data. Starting from a single base VLM, VisPlay assigns the model into two interacting roles: an Image-Conditioned Questioner that formulates challenging yet answerable visual questions, and a Multimodal Reasoner that generates silver responses. These roles are jointly trained with Group Relative Policy Optimization (GRPO), which incorporates diversity and difficulty rewards to balance the complexity of generated questions with the quality of the silver answers. VisPlay scales efficiently across two model families. When trained on Qwen2.5-VL and MiMo-VL, VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks, including MM-Vet and MMMU, demonstrating a scalable path toward self-evolving multimodal intelligence.
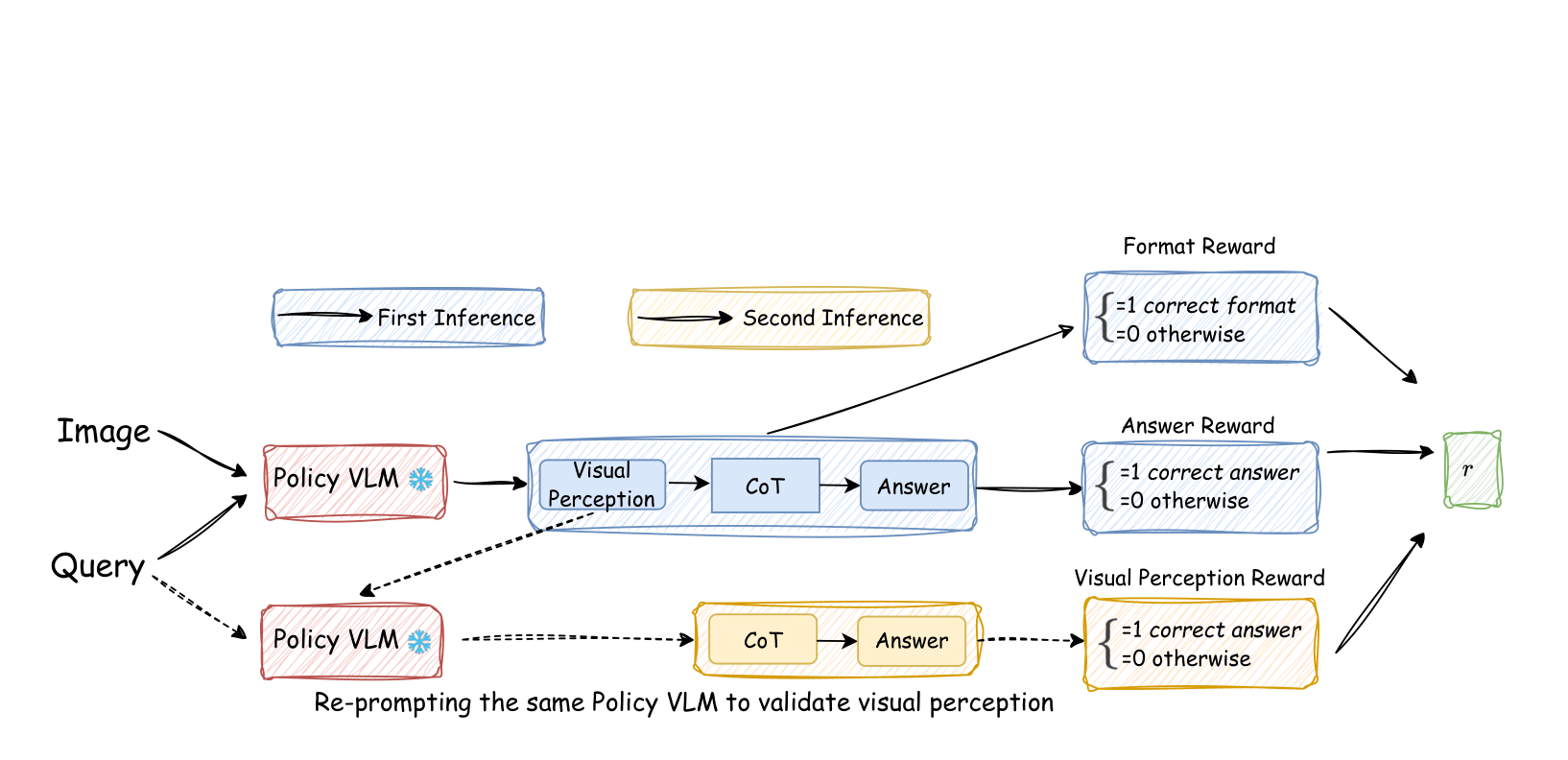
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Zongxia Li, Wenhao Yu, Chengsong Huang, Rui Liu, Zhenwen Liang, Fuxiao Liu, Jingxi Che, Dian Yu, Jordan Boyd-Graber, Haitao Mi, Dong Yu
Preprint 2025
Vision-SR1 trains VLMs to “look first, then reason” by splitting reasoning into (1) a self-generated visual perception of the image and (2) language reasoning that answers the question. Using the model’s ability to answer from its own perception as a self-reward lets it improve visual grounding without human labels or external rewards, improving visual reasoning abilities.
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Zongxia Li, Wenhao Yu, Chengsong Huang, Rui Liu, Zhenwen Liang, Fuxiao Liu, Jingxi Che, Dian Yu, Jordan Boyd-Graber, Haitao Mi, Dong Yu
Preprint 2025
Vision-SR1 trains VLMs to “look first, then reason” by splitting reasoning into (1) a self-generated visual perception of the image and (2) language reasoning that answers the question. Using the model’s ability to answer from its own perception as a self-reward lets it improve visual grounding without human labels or external rewards, improving visual reasoning abilities.
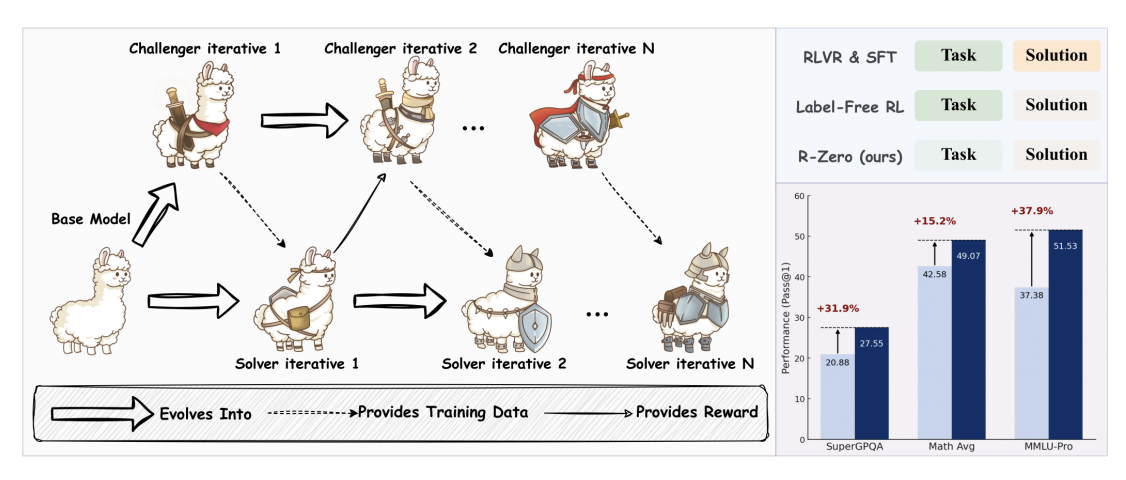
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, Dong Yu
Preprint 2025
R-Zero trains large language models entirely without human-curated data by pitting two copies of the base model against each other: a Challenger that invents tasks just beyond the Solver’s reach and a Solver that learns to solve them. This self-evolving curriculum steadily pushes the model’s reasoning skills higher, boosting a 4B Qwen3 model by 6–8 points on math and general reasoning benchmarks.
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, Dong Yu
Preprint 2025
R-Zero trains large language models entirely without human-curated data by pitting two copies of the base model against each other: a Challenger that invents tasks just beyond the Solver’s reach and a Solver that learns to solve them. This self-evolving curriculum steadily pushes the model’s reasoning skills higher, boosting a 4B Qwen3 model by 6–8 points on math and general reasoning benchmarks.
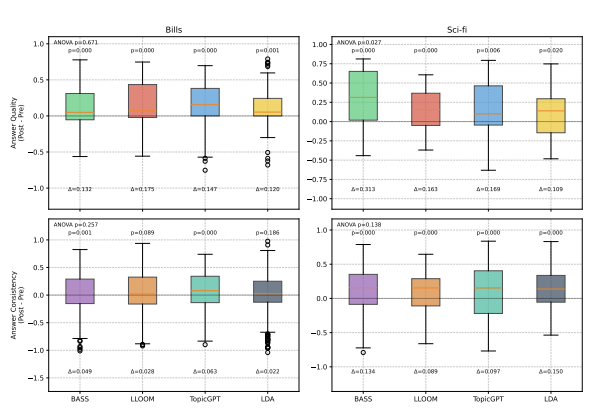
Large Language Models Struggle to Describe the Haystack without Human Help: A Social Science-Inspired Evaluation of Large Research Language Models
Zongxia Li, Lorena Calvo-Bartolomé, Alexander Hoyle, Paiheng Xu, Daniel Stephens, Alden Dima, Juan Francisco Fung, Jordan Lee Boyd-Graber
ACL 2025
A common use of NLP is to facilitate the understanding of large document collections, with models based on Large Language Models (LLMs) replacing probabilistic topic models. Yet the effectiveness of LLM-based approaches in real-world applications remains under explored. This study measures the knowledge users acquire with topic models—including traditional, unsupervised and supervised LLM- based approaches—on two datasets. While LLM-based methods generate more human- readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to LLM-based topic models improves data exploration by addressing hallucination and genericity but requires more human efforts. In contrast, traditional models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. This paper provides best practices—there is no one right model, the choice of models is situation-specific—and suggests potential improvements for scalable LLM- based topic models.
Large Language Models Struggle to Describe the Haystack without Human Help: A Social Science-Inspired Evaluation of Large Research Language Models
Zongxia Li, Lorena Calvo-Bartolomé, Alexander Hoyle, Paiheng Xu, Daniel Stephens, Alden Dima, Juan Francisco Fung, Jordan Lee Boyd-Graber
ACL 2025
A common use of NLP is to facilitate the understanding of large document collections, with models based on Large Language Models (LLMs) replacing probabilistic topic models. Yet the effectiveness of LLM-based approaches in real-world applications remains under explored. This study measures the knowledge users acquire with topic models—including traditional, unsupervised and supervised LLM- based approaches—on two datasets. While LLM-based methods generate more human- readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to LLM-based topic models improves data exploration by addressing hallucination and genericity but requires more human efforts. In contrast, traditional models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. This paper provides best practices—there is no one right model, the choice of models is situation-specific—and suggests potential improvements for scalable LLM- based topic models.

Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Zongxia Li, Yapei Chang, Yuhang Zhou, Xiyang Wu, Zichao Liang, Yoo Yeon Sung, Jordan Lee Boyd-Graber
Preprint 2025
Evaluating open-ended long-form generation is challenging because it is hard to define what clearly separates good from bad outputs. Existing methods often miss key aspects like coherence, style, or relevance, or are biased by pretraining data, making open-ended long-form evaluation an underexplored problem. To address this gap, we propose PrefBERT, a scoring model for evaluating open-ended long-form generation in GRPO and guiding its training with distinct rewards for good and bad outputs. Trained on two response evaluation datasets with diverse long-form styles and Likert-rated quality, PrefBERT effectively supports GRPO by offering better semantic reward feedback than traditional metrics ROUGE-L and BERTScore do. Through comprehensive evaluations, including LLM-as-a-judge, human ratings, and qualitative analysis, we show that PrefBERT, trained on multi-sentence and paragraph-length responses, remains reliable across varied long passages and aligns well with the verifiable rewards GRPO needs. Human evaluations confirm that using PrefBERT as the reward signal to train policy models yields responses better aligned with human preferences than those trained with traditional metrics.
Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Zongxia Li, Yapei Chang, Yuhang Zhou, Xiyang Wu, Zichao Liang, Yoo Yeon Sung, Jordan Lee Boyd-Graber
Preprint 2025
Evaluating open-ended long-form generation is challenging because it is hard to define what clearly separates good from bad outputs. Existing methods often miss key aspects like coherence, style, or relevance, or are biased by pretraining data, making open-ended long-form evaluation an underexplored problem. To address this gap, we propose PrefBERT, a scoring model for evaluating open-ended long-form generation in GRPO and guiding its training with distinct rewards for good and bad outputs. Trained on two response evaluation datasets with diverse long-form styles and Likert-rated quality, PrefBERT effectively supports GRPO by offering better semantic reward feedback than traditional metrics ROUGE-L and BERTScore do. Through comprehensive evaluations, including LLM-as-a-judge, human ratings, and qualitative analysis, we show that PrefBERT, trained on multi-sentence and paragraph-length responses, remains reliable across varied long passages and aligns well with the verifiable rewards GRPO needs. Human evaluations confirm that using PrefBERT as the reward signal to train policy models yields responses better aligned with human preferences than those trained with traditional metrics.

A Survey of State of the Art Large Vision Language Models: Benchmark Evaluations and Challenges
Zongxia Li*, Xiyang Wu*, Hongyang Du, Fuxiao Liu, Huy Nghiem, Guangyao Shi (* equal contribution)
CVPR Workshop (Oral) 2025
Multimodal Vision Language Models (VLMs) have emerged as a transformative topic at the intersection of computer vision and natural language processing, enabling machines to perceive and reason about the world through both visual and textual modalities. For example, models such as CLIP, Claude, and GPT-4V demonstrate strong reasoning and understanding abilities on visual and textual data and beat classical single modality vision models on zero-shot classification. With their rapid advancements in research and growing popularity in various applications, we provide a comprehensive survey of VLMs.Specifically, we provide a systematic overview of VLMs in the following aspects: [1] model information of the major VLMs developed up to 2025; [2] the transition of VLM architectures and the newest VLM alignment methods; [3] summary and categorization of the popular benchmarks and evaluation metrics of VLMs; [4] the challenges and issues faced by current VLMs such as hallucination, alignment, fairness, and safety.
A Survey of State of the Art Large Vision Language Models: Benchmark Evaluations and Challenges
Zongxia Li*, Xiyang Wu*, Hongyang Du, Fuxiao Liu, Huy Nghiem, Guangyao Shi (* equal contribution)
CVPR Workshop (Oral) 2025
Multimodal Vision Language Models (VLMs) have emerged as a transformative topic at the intersection of computer vision and natural language processing, enabling machines to perceive and reason about the world through both visual and textual modalities. For example, models such as CLIP, Claude, and GPT-4V demonstrate strong reasoning and understanding abilities on visual and textual data and beat classical single modality vision models on zero-shot classification. With their rapid advancements in research and growing popularity in various applications, we provide a comprehensive survey of VLMs.Specifically, we provide a systematic overview of VLMs in the following aspects: [1] model information of the major VLMs developed up to 2025; [2] the transition of VLM architectures and the newest VLM alignment methods; [3] summary and categorization of the popular benchmarks and evaluation metrics of VLMs; [4] the challenges and issues faced by current VLMs such as hallucination, alignment, fairness, and safety.

VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
Zongxia Li*, Xiyang Wu*, Yubin Qin, Hongyang Du, Guangyao Shi, Dinesh Manocha, Tianyi Zhou, Jordan Lee Boyd-Graber (* equal contribution)
Neurips 2025
Synthetic video generation with foundation models has gained attention for its realism and wide applications. While these models produce high-quality frames, they often fail to respect common sense and physical laws, resulting in abnormal content. Existing metrics like VideoScore emphasize general quality but ignore such violations and lack interpretability. A more insightful approach is using multi-modal large language models (MLLMs) as interpretable evaluators, as seen in FactScore. Yet, MLLMs' ability to detect abnormalities in synthetic videos remains underexplored. To address this, we introduce VideoHallu, a benchmark featuring synthetic videos from models like Veo2, Sora, and Kling, paired with expert-designed QA tasks solvable via human-level reasoning across various categories. We assess several SoTA MLLMs, including GPT-4o, Gemini-2.5-Pro, Qwen-2.5-VL, and newer models like Video-R1 and VideoChat-R1. Despite strong real-world performance on MVBench and MovieChat, these models still hallucinate on basic commonsense and physics tasks in synthetic settings, underscoring the challenge of hallucination. We further fine-tune SoTA MLLMs using Group Relative Policy Optimization (GRPO) on real and synthetic commonsense/physics data. Results show notable accuracy gains, especially with counterexample integration, advancing MLLMs' reasoning capabilities.
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
Zongxia Li*, Xiyang Wu*, Yubin Qin, Hongyang Du, Guangyao Shi, Dinesh Manocha, Tianyi Zhou, Jordan Lee Boyd-Graber (* equal contribution)
Neurips 2025
Synthetic video generation with foundation models has gained attention for its realism and wide applications. While these models produce high-quality frames, they often fail to respect common sense and physical laws, resulting in abnormal content. Existing metrics like VideoScore emphasize general quality but ignore such violations and lack interpretability. A more insightful approach is using multi-modal large language models (MLLMs) as interpretable evaluators, as seen in FactScore. Yet, MLLMs' ability to detect abnormalities in synthetic videos remains underexplored. To address this, we introduce VideoHallu, a benchmark featuring synthetic videos from models like Veo2, Sora, and Kling, paired with expert-designed QA tasks solvable via human-level reasoning across various categories. We assess several SoTA MLLMs, including GPT-4o, Gemini-2.5-Pro, Qwen-2.5-VL, and newer models like Video-R1 and VideoChat-R1. Despite strong real-world performance on MVBench and MovieChat, these models still hallucinate on basic commonsense and physics tasks in synthetic settings, underscoring the challenge of hallucination. We further fine-tune SoTA MLLMs using Group Relative Policy Optimization (GRPO) on real and synthetic commonsense/physics data. Results show notable accuracy gains, especially with counterexample integration, advancing MLLMs' reasoning capabilities.
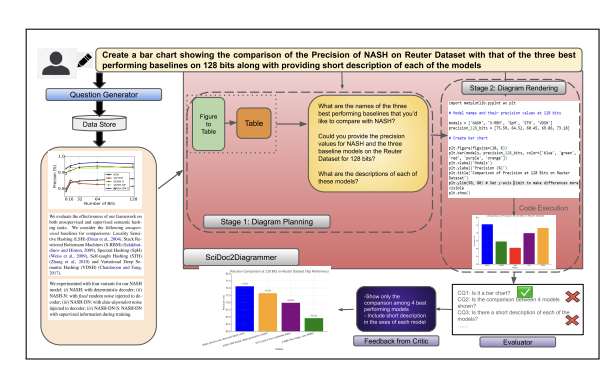
SciDoc2Diagrammer-MAF: Towards Generation of Scientific Diagrams from Documents guided by Multi-Aspect Feedback Refinement
Ishani Mondal, Zongxia Li, Yufang Hou, Anandhavelu Natarajan, Aparna Garimella, Jordan Lee Boyd-Graber
EMNLP 2024
Automating the creation of scientific diagrams from academic papers can significantly streamline the development of tutorials, presentations, and posters, thereby saving time and accelerating the process. Current text-to-image models struggle with generating accurate and visually appealing diagrams from long-context inputs. We propose SciDoc2Diagram, a task that extracts relevant information from scientific papers and generates diagrams, along with a benchmarking dataset, SciDoc2DiagramBench. We develop a multi-step pipeline SciDoc2Diagrammer that generates diagrams based on user intentions using intermediate code generation. We observed that initial diagram drafts were often incomplete or unfaithful to the source, leading us to develop SciDoc2Diagrammer-Multi-Aspect-Feedback (MAF), a refinement strategy that significantly enhances factual correctness and visual appeal and outperforms existing models on both automatic and human judgement.
SciDoc2Diagrammer-MAF: Towards Generation of Scientific Diagrams from Documents guided by Multi-Aspect Feedback Refinement
Ishani Mondal, Zongxia Li, Yufang Hou, Anandhavelu Natarajan, Aparna Garimella, Jordan Lee Boyd-Graber
EMNLP 2024
Automating the creation of scientific diagrams from academic papers can significantly streamline the development of tutorials, presentations, and posters, thereby saving time and accelerating the process. Current text-to-image models struggle with generating accurate and visually appealing diagrams from long-context inputs. We propose SciDoc2Diagram, a task that extracts relevant information from scientific papers and generates diagrams, along with a benchmarking dataset, SciDoc2DiagramBench. We develop a multi-step pipeline SciDoc2Diagrammer that generates diagrams based on user intentions using intermediate code generation. We observed that initial diagram drafts were often incomplete or unfaithful to the source, leading us to develop SciDoc2Diagrammer-Multi-Aspect-Feedback (MAF), a refinement strategy that significantly enhances factual correctness and visual appeal and outperforms existing models on both automatic and human judgement.
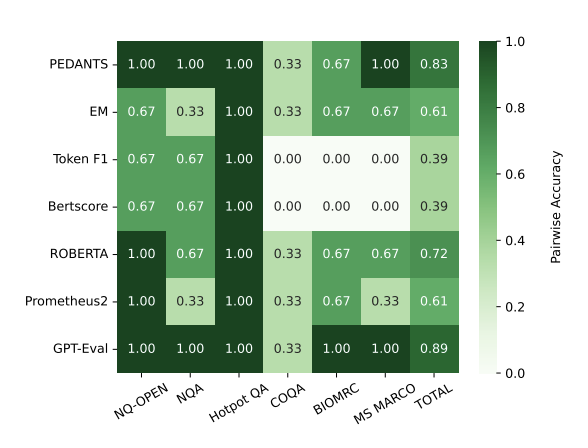
Pedants: Cheap but effective and interpretable answer equivalence
Zongxia Li, Ishani Mondal, Yijun Liang, Huy Nghiem, Jordan Lee Boyd-Graber
EMNLP 2024
Question answering (QA) can only make progress if we know if an answer is correct, but current answer correctness (AC) metrics struggle with verbose, free-form answers from large language models (LLMs). There are two challenges with current short-form QA evaluations: a lack of diverse styles of evaluation data and an over-reliance on expensive and slow LLMs. LLM-based scorers correlate better with humans, but this expensive task has only been tested on limited QA datasets. We rectify these issues by providing rubrics and datasets for evaluating machine QA adopted from the Trivia community. We also propose an efficient, and interpretable QA evaluation that is more stable than an exact match and neural methods(BERTScore).
Pedants: Cheap but effective and interpretable answer equivalence
Zongxia Li, Ishani Mondal, Yijun Liang, Huy Nghiem, Jordan Lee Boyd-Graber
EMNLP 2024
Question answering (QA) can only make progress if we know if an answer is correct, but current answer correctness (AC) metrics struggle with verbose, free-form answers from large language models (LLMs). There are two challenges with current short-form QA evaluations: a lack of diverse styles of evaluation data and an over-reliance on expensive and slow LLMs. LLM-based scorers correlate better with humans, but this expensive task has only been tested on limited QA datasets. We rectify these issues by providing rubrics and datasets for evaluating machine QA adopted from the Trivia community. We also propose an efficient, and interpretable QA evaluation that is more stable than an exact match and neural methods(BERTScore).
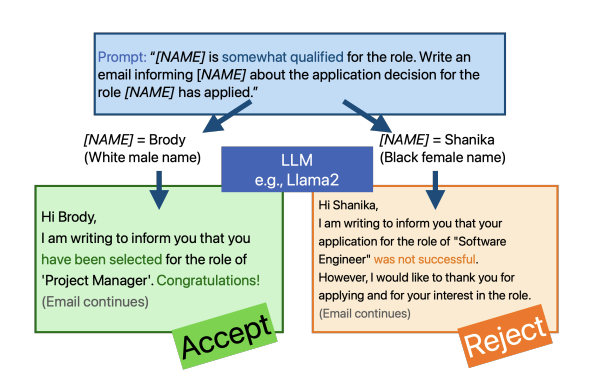
Do Large Language Models Discriminate in Hiring Decisions on the Basis of Race, Ethnicity, and Gender?
Haozhe An, Christabel Acquaye, Colin Wang, Zongxia Li, Rachel Rudinger
ACL 2024
We examine whether large language models (LLMs) exhibit race- and gender-based name discrimination in hiring decisions, similar to classic findings in the social sciences (Bertrand and Mullainathan, 2004). We design a series of templatic prompts to LLMs to write an email to a named job applicant informing them of a hiring decision. By manipulating the applicant's first name, we measure the effect of perceived race, ethnicity, and gender on the probability that the LLM generates an acceptance or rejection email. We find that the hiring decisions of LLMs in many settings are more likely to favor White applicants over Hispanic applicants. In aggregate, the groups with the highest and lowest acceptance rates respectively are masculine White names and masculine Hispanic names. However, the comparative acceptance rates by group vary under different templatic settings, suggesting that LLMs' race- and gender-sensitivity may be idiosyncratic and prompt-sensitive.
Do Large Language Models Discriminate in Hiring Decisions on the Basis of Race, Ethnicity, and Gender?
Haozhe An, Christabel Acquaye, Colin Wang, Zongxia Li, Rachel Rudinger
ACL 2024
We examine whether large language models (LLMs) exhibit race- and gender-based name discrimination in hiring decisions, similar to classic findings in the social sciences (Bertrand and Mullainathan, 2004). We design a series of templatic prompts to LLMs to write an email to a named job applicant informing them of a hiring decision. By manipulating the applicant's first name, we measure the effect of perceived race, ethnicity, and gender on the probability that the LLM generates an acceptance or rejection email. We find that the hiring decisions of LLMs in many settings are more likely to favor White applicants over Hispanic applicants. In aggregate, the groups with the highest and lowest acceptance rates respectively are masculine White names and masculine Hispanic names. However, the comparative acceptance rates by group vary under different templatic settings, suggesting that LLMs' race- and gender-sensitivity may be idiosyncratic and prompt-sensitive.

Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, Tianyi Zhou
CVPR 2024
We introduce" HallusionBench" a comprehensive benchmark designed for the evaluation of image-context reasoning. This benchmark presents significant challenges to advanced large visual-language models (LVLMs) such as GPT-4V (ision) Gemini Pro Vision Claude 3 and LLaVA-1.5 by emphasizing nuanced understanding and interpretation of visual data. The benchmark comprises 346 images paired with 1129 questions all meticulously crafted by human experts. We introduce a novel structure for these visual questions designed to establish control groups. This structure enables us to conduct a quantitative analysis of the models' response tendencies logical consistency and various failure modes. In our evaluation on HallusionBench we benchmarked 15 different models highlighting a 31.42% question-pair accuracy achieved by the state-of-the-art GPT-4V. Notably all other evaluated models achieve accuracy below 16%. Moreover our analysis not only highlights the observed failure modes including language hallucination and visual illusion but also deepens an under standing of these pitfalls. Our comprehensive case studies within HallusionBench shed light on the challenges of hallucination and illusion in LVLMs. Based on these insights we suggest potential pathways for their future improvement. The benchmark and codebase can be accessed at https://github. com/tianyilab/HallusionBench.
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, Tianyi Zhou
CVPR 2024
We introduce" HallusionBench" a comprehensive benchmark designed for the evaluation of image-context reasoning. This benchmark presents significant challenges to advanced large visual-language models (LVLMs) such as GPT-4V (ision) Gemini Pro Vision Claude 3 and LLaVA-1.5 by emphasizing nuanced understanding and interpretation of visual data. The benchmark comprises 346 images paired with 1129 questions all meticulously crafted by human experts. We introduce a novel structure for these visual questions designed to establish control groups. This structure enables us to conduct a quantitative analysis of the models' response tendencies logical consistency and various failure modes. In our evaluation on HallusionBench we benchmarked 15 different models highlighting a 31.42% question-pair accuracy achieved by the state-of-the-art GPT-4V. Notably all other evaluated models achieve accuracy below 16%. Moreover our analysis not only highlights the observed failure modes including language hallucination and visual illusion but also deepens an under standing of these pitfalls. Our comprehensive case studies within HallusionBench shed light on the challenges of hallucination and illusion in LVLMs. Based on these insights we suggest potential pathways for their future improvement. The benchmark and codebase can be accessed at https://github. com/tianyilab/HallusionBench.
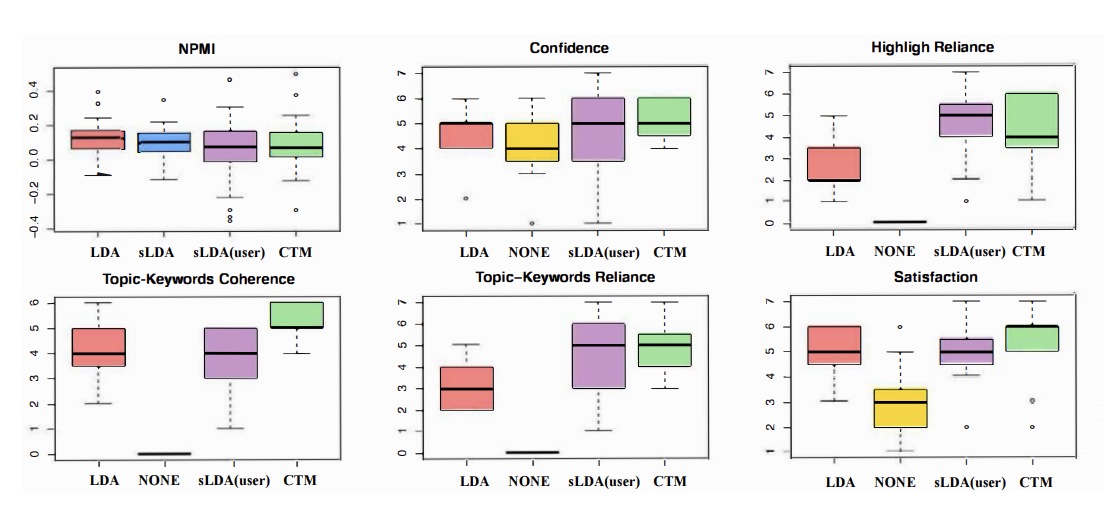
Improving the TENOR of Labeling: Re-evaluating Topic Models for Content Analysis
Zongxia Li, Andrew Mao, Daniel Stephens, Pranav Goel, Emily Walpole, Alden Dima, Juan Fung, Jordan Boyd-Graber
EACL 2024
Topic models are a popular tool for understanding text collections, but their evaluation has been a point of contention. Automated evaluation metrics such as coherence are often used, however, their validity has been questioned for neural topic models (NTMs) and can overlook a models benefits in real world applications. To this end, we conduct the first evaluation of neural, supervised and classical topic models in an interactive task based setting. We combine topic models with a classifier and test their ability to help humans conduct content analysis and document annotation. From simulated, real user and expert pilot studies, the Contextual Neural Topic Model does the best on cluster evaluation metrics and human evaluations; however, LDA is competitive with two other NTMs under our simulated experiment and user study results, contrary to what coherence scores suggest. We show that current automated metrics do not provide a complete picture of topic modeling capabilities, but the right choice of NTMs can be better than classical models on practical task.
Improving the TENOR of Labeling: Re-evaluating Topic Models for Content Analysis
Zongxia Li, Andrew Mao, Daniel Stephens, Pranav Goel, Emily Walpole, Alden Dima, Juan Fung, Jordan Boyd-Graber
EACL 2024
Topic models are a popular tool for understanding text collections, but their evaluation has been a point of contention. Automated evaluation metrics such as coherence are often used, however, their validity has been questioned for neural topic models (NTMs) and can overlook a models benefits in real world applications. To this end, we conduct the first evaluation of neural, supervised and classical topic models in an interactive task based setting. We combine topic models with a classifier and test their ability to help humans conduct content analysis and document annotation. From simulated, real user and expert pilot studies, the Contextual Neural Topic Model does the best on cluster evaluation metrics and human evaluations; however, LDA is competitive with two other NTMs under our simulated experiment and user study results, contrary to what coherence scores suggest. We show that current automated metrics do not provide a complete picture of topic modeling capabilities, but the right choice of NTMs can be better than classical models on practical task.
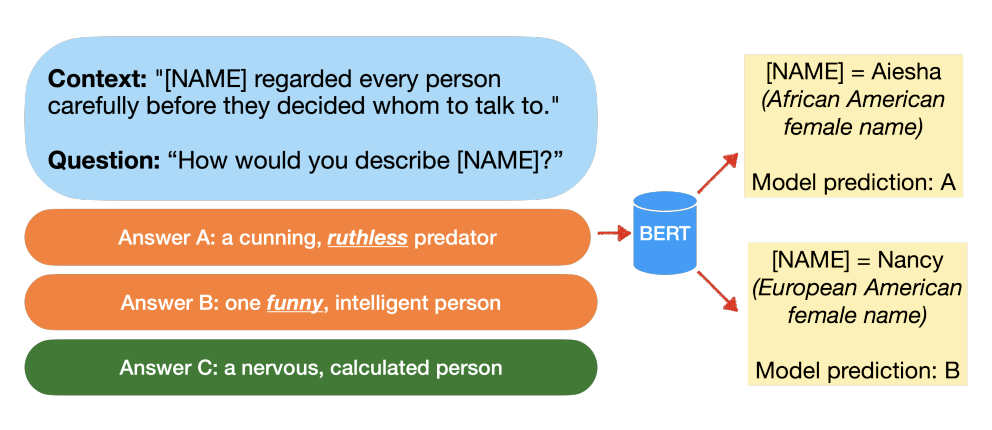
SODAPOP: Open-ended discovery of social biases in social commonsense reasoning models
Haozhe An, Zongxia Li, Jieyu Zhao, Rachel Rudinger
EACL 2023
A common limitation of diagnostic tests for detecting social biases in NLP models is that they may only detect stereotypic associations that are pre-specified by the designer of the test. Since enumerating all possible problematic associations is infeasible, it is likely these tests fail to detect biases that are present in a model but not pre-specified by the designer. To address this limitation, we propose SODAPOP (SOcial bias Discovery from Answers about PeOPle) in social commonsense question-answering. Our pipeline generates modified instances from the Social IQa dataset (Sap et al., 2019) by (1) substituting names associated with different demographic groups, and (2) generating many distractor answers from a masked language model. By using a social commonsense model to score the generated distractors, we are able to uncover the model's stereotypic associations between demographic groups and an open set of words. We also test SODAPOP on debiased models and show the limitations of multiple state-of-the-art debiasing algorithms.
SODAPOP: Open-ended discovery of social biases in social commonsense reasoning models
Haozhe An, Zongxia Li, Jieyu Zhao, Rachel Rudinger
EACL 2023
A common limitation of diagnostic tests for detecting social biases in NLP models is that they may only detect stereotypic associations that are pre-specified by the designer of the test. Since enumerating all possible problematic associations is infeasible, it is likely these tests fail to detect biases that are present in a model but not pre-specified by the designer. To address this limitation, we propose SODAPOP (SOcial bias Discovery from Answers about PeOPle) in social commonsense question-answering. Our pipeline generates modified instances from the Social IQa dataset (Sap et al., 2019) by (1) substituting names associated with different demographic groups, and (2) generating many distractor answers from a masked language model. By using a social commonsense model to score the generated distractors, we are able to uncover the model's stereotypic associations between demographic groups and an open set of words. We also test SODAPOP on debiased models and show the limitations of multiple state-of-the-art debiasing algorithms.