
About me
I am a fourth-year PhD candidate in Computer Science at the University of Maryland, College Park, in the CLIP Lab, advised by Jordan Boyd-Graber and co-advised by Lichao Sun. My research develops methods that make vision-language models and agents more capable through post-training, more autonomous through self-evolution, and more useful through tighter collaboration with humans.
Research Focus
Self-Evolving Agents — Autonomous agents that bootstrap their own capabilities from minimal or zero human-curated data, spanning self-evolving multimodal reasoning, co-evolving decision-and-skill agents for long-horizon tasks, and exploration-guided visual reasoning.
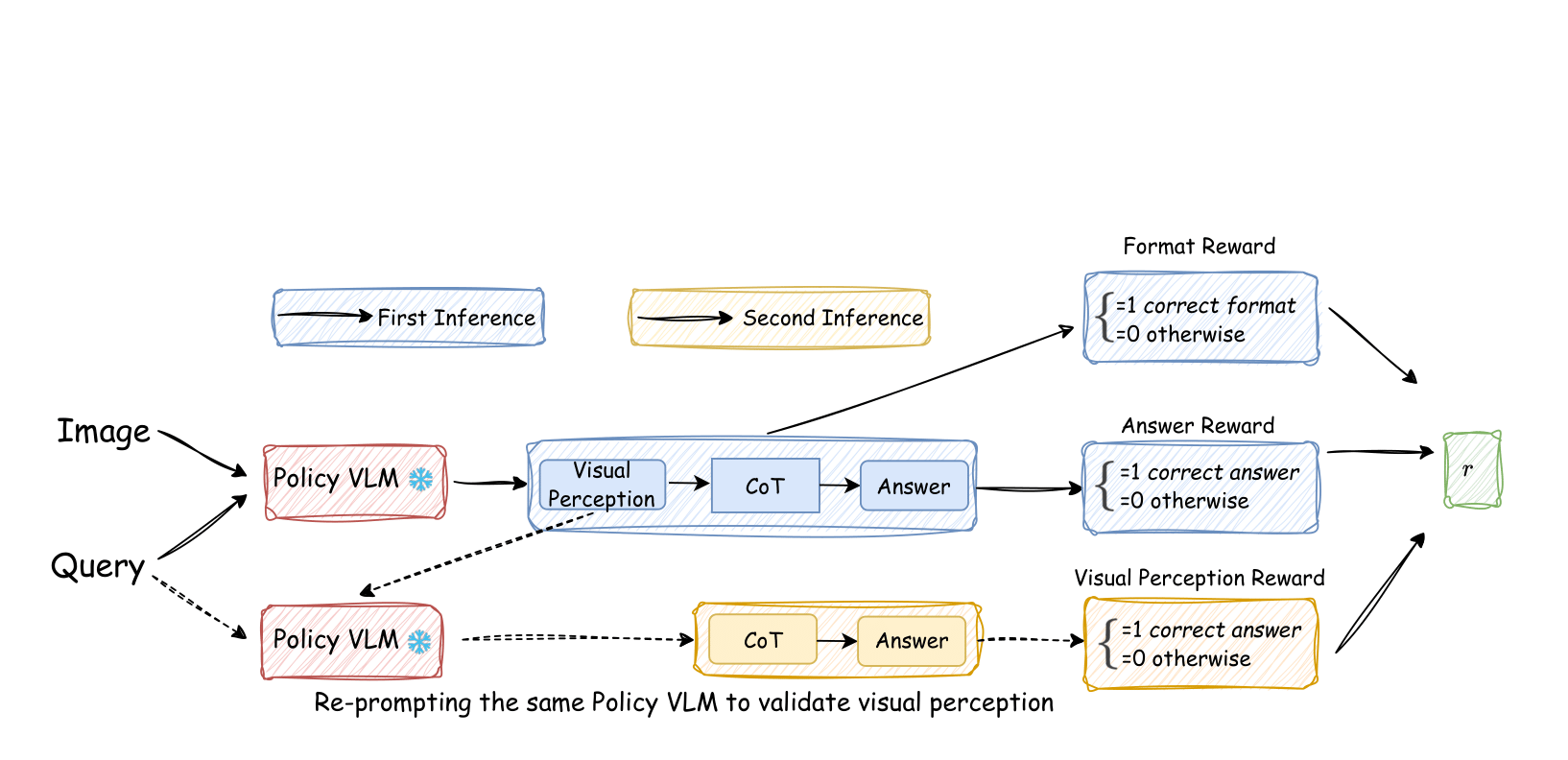
Model Post-Training — Reinforcement learning and reward design for vision-language models, including self-rewarding via reasoning decomposition, semantically-aware open-ended rewards, and hallucination-targeted alignment for image and video understanding.
Human-AI Collaboration — How humans and AI systems collaborate to optimize real-world workflows, from LLM-assisted annotation and interactive topic exploration to robust automatic evaluation metrics that faithfully reflect human judgment.
News
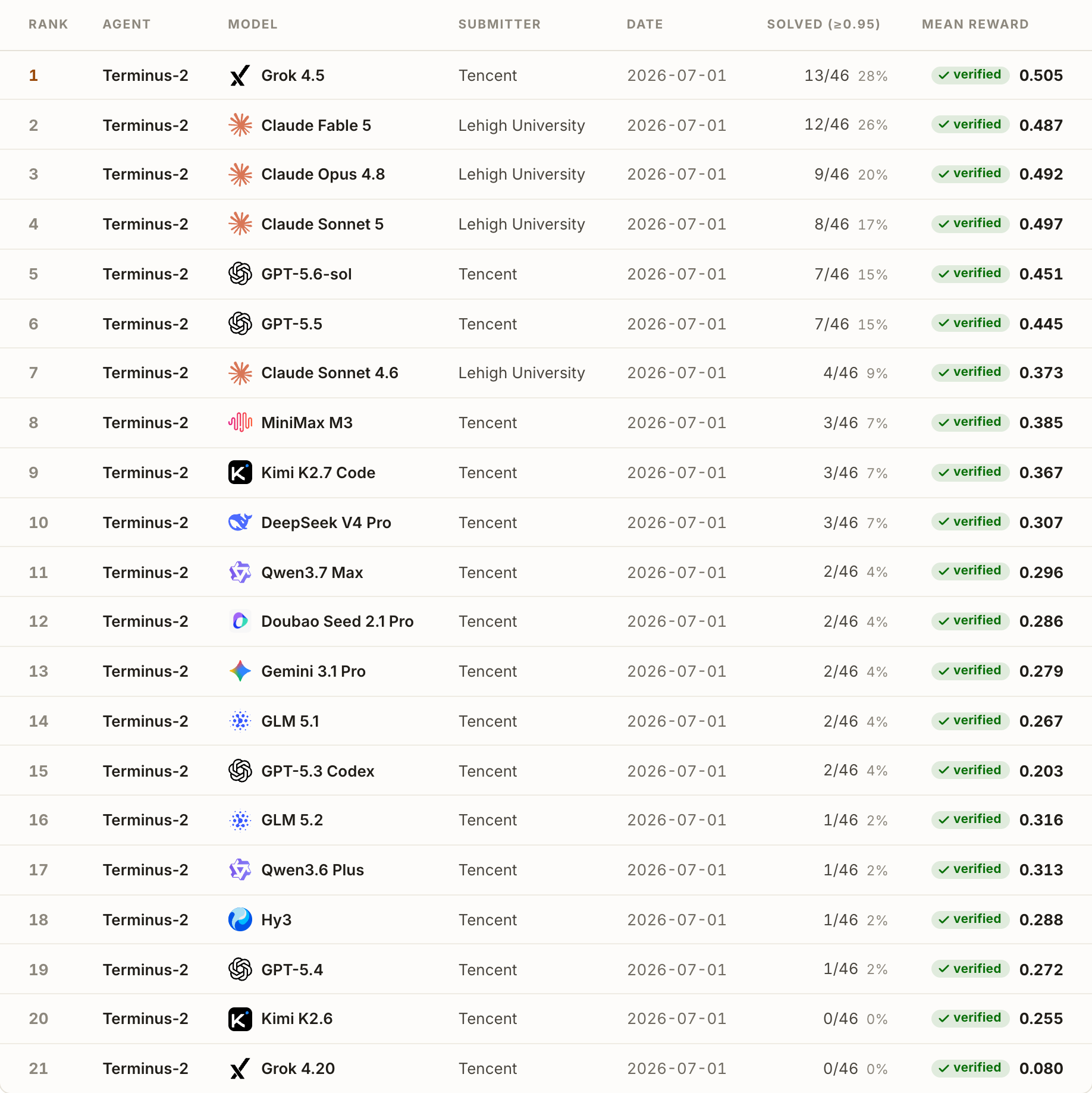
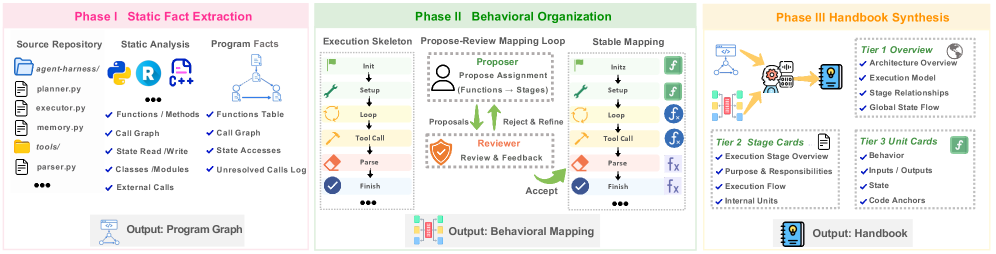
| Jul 14, 2026 | Harness Handbook is released! Making evolving agent harnesses readable, navigable, and editable. |
| Jul 9, 2026 | Long-Horizon-Terminal-Bench (LHTB) is released! Testing the limits of agents on long-horizon terminal tasks with dense reward-based grading. |
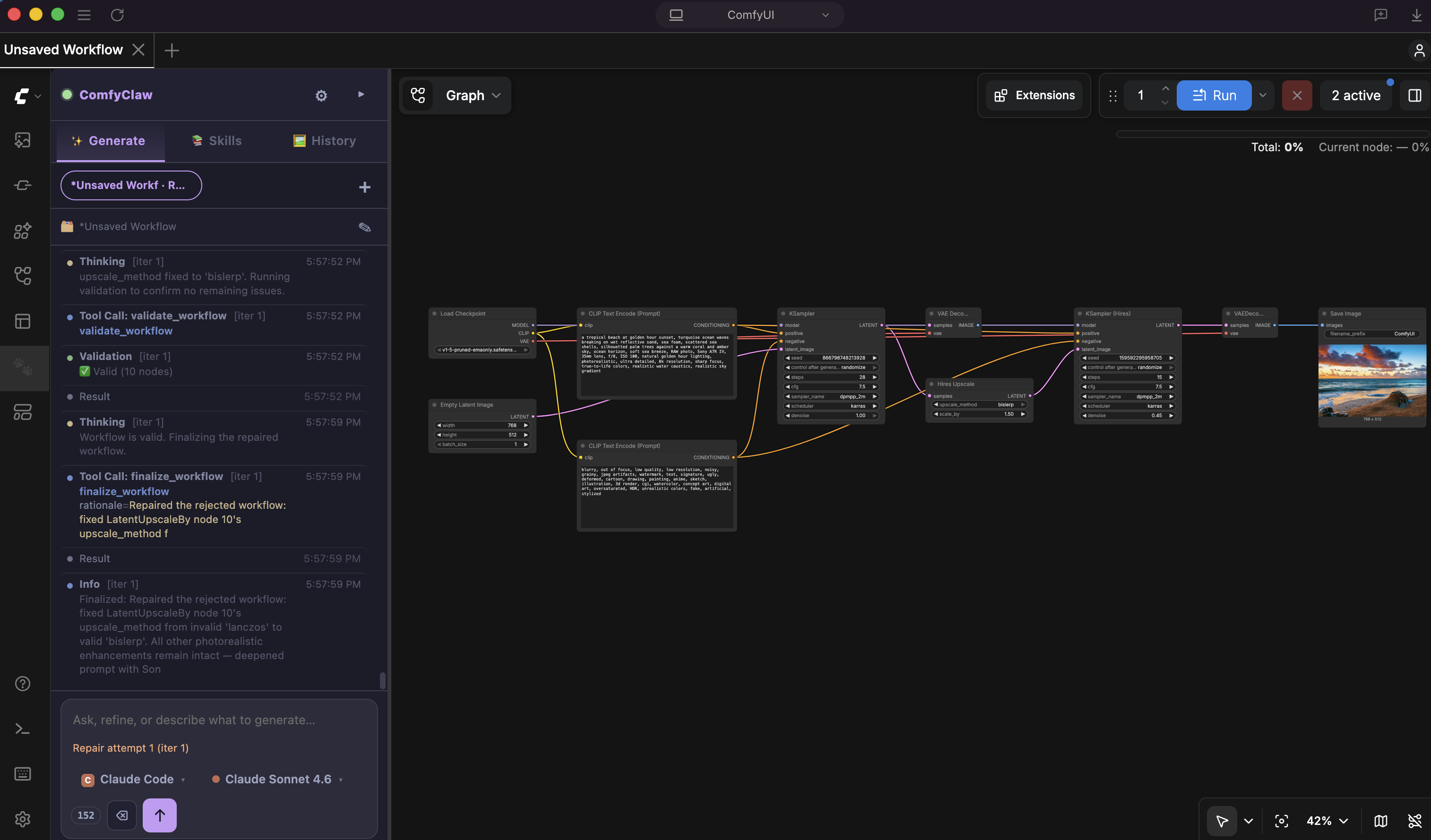
| May 1, 2026 | ComfyClaw is released! An agentic harness for skill-evolving image generation workflows. |
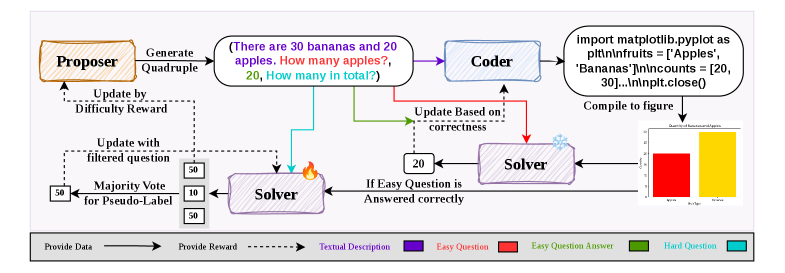
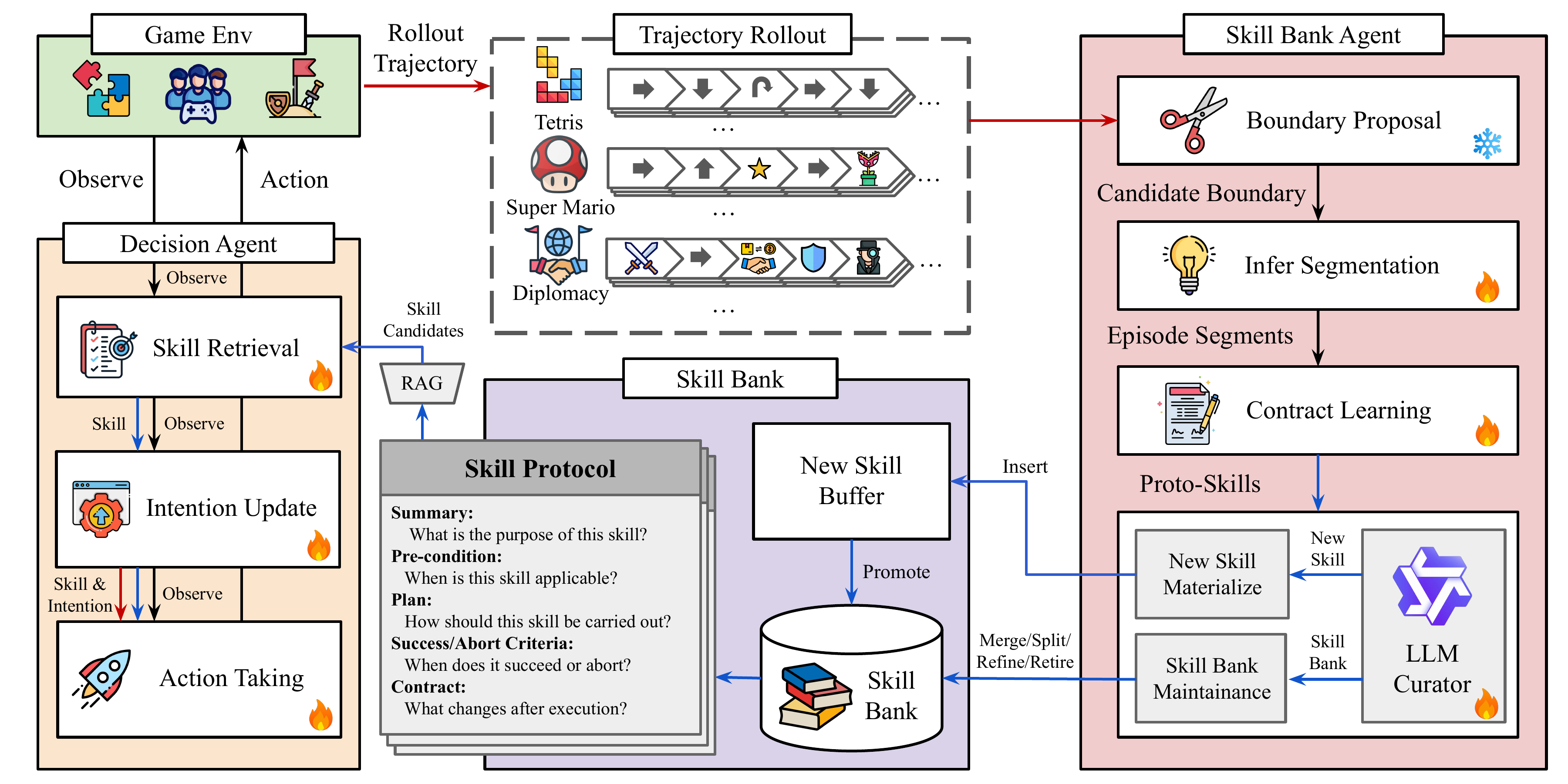
| Apr 29, 2026 | COS-PLAY is released! Co-evolving LLM decision and skill bank agents for long-horizon tasks. |
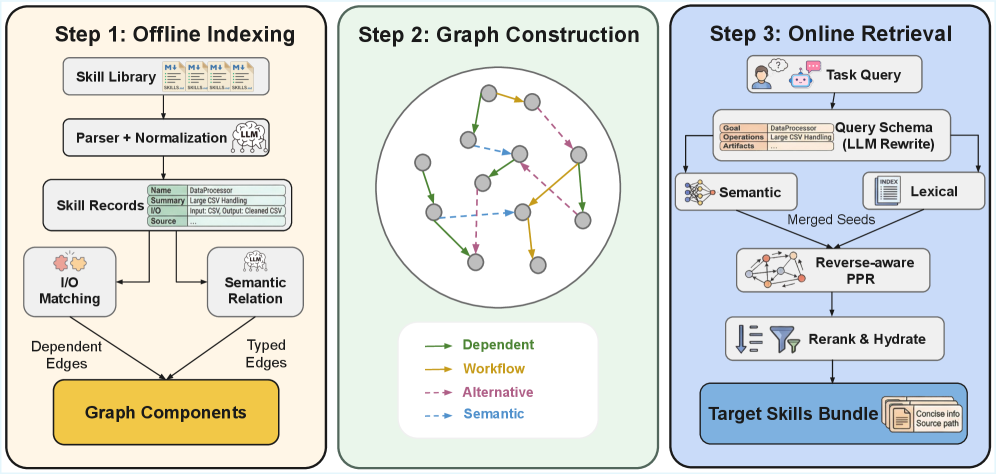
| Apr 7, 2026 | Graph-of-Skills is released! Dependency-aware structural retrieval for massive agent skills. |
| Mar 10, 2026 | MM-Zero is released! Self-evolving VLMs from zero data using multi-role RL training. |
| Feb 20, 2026 | FFGO, VisPlay, and MASS are accepted to CVPR 2026. |
| Feb 8, 2026 | R-Zero and Vision-SR1 are accepted to ICLR 2026. |
| Nov 20, 2025 | FFGO is released! Customize your video with our FFGO LoRA adapters. |
| Nov 19, 2025 | VisPlay is released! Learn how to evolve VLMs with just images. |
| Sep 20, 2025 | VideoHallu is accepted to NeurIPS 2025. |
| Aug 22, 2025 | I finished my internship at Tencent AI Lab, Bellevue, mentored by Wenhao Yu, working on self-evolving VLMs and LLMs. |
| Jul 22, 2025 | I received a research compute grant from Lambda Labs. |
| Aug 22, 2024 | I finished my internship at Adobe Document Intelligence Lab, focusing on improving LLM automatic evaluations for downstream training. |
Selected Publications


Popular Community Projects
A super AI lab with massive AI doctors as assistants — the best IDE for research powered by AI.
A comprehensive, continuously updated collection of VLM benchmarks, RL alignment methods, and applications.