Zongxia Li
Publications
Projects
CV
Zongxia Li
PhD Candidate,
CLIP Lab
Follow
College Park, MD
University of Maryland
Email
Google Scholar
GitHub
LinkedIn
X
Publications
You can also find my articles on
my Google Scholar profile
.
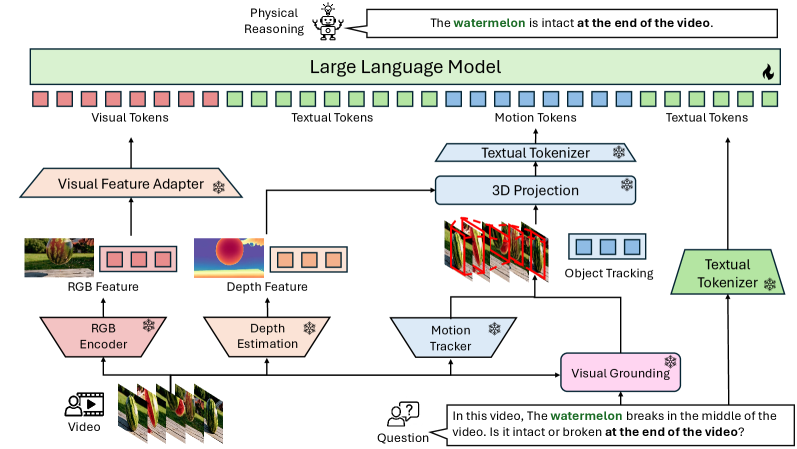
MASS: Motion-Aware Spatial-Temporal Grounding for Physics Reasoning and Comprehension in Vision-Language Models
Xiyang Wu,
Zongxia Li
, Jihui Jin, Guangyao Shi, Gouthaman KV, Vishnu Raj, Nilotpal Sinha, Jingxi Chen, Fan Du, Dinesh Manocha
CVPR 2026
[paper]
VisPlay: Self-Evolving Vision-Language Models from Images
Yicheng He*, Chengsong Huang*,
Zongxia Li
*, Jiaxin Huang, Yonghui Yang
CVPR 2026
[paper]
[webpage]
First Frame Is the Place to Go for Video Content Customization
Jingxi Chen*,
Zongxia Li
*, Zhichao Liu, Guangyao Shi, Xiyang Wu, Fuxiao Liu, Cornelia Fermüller, Brandon Y. Feng, Yiannis Aloimonos
CVPR 2026
[paper]
[webpage]
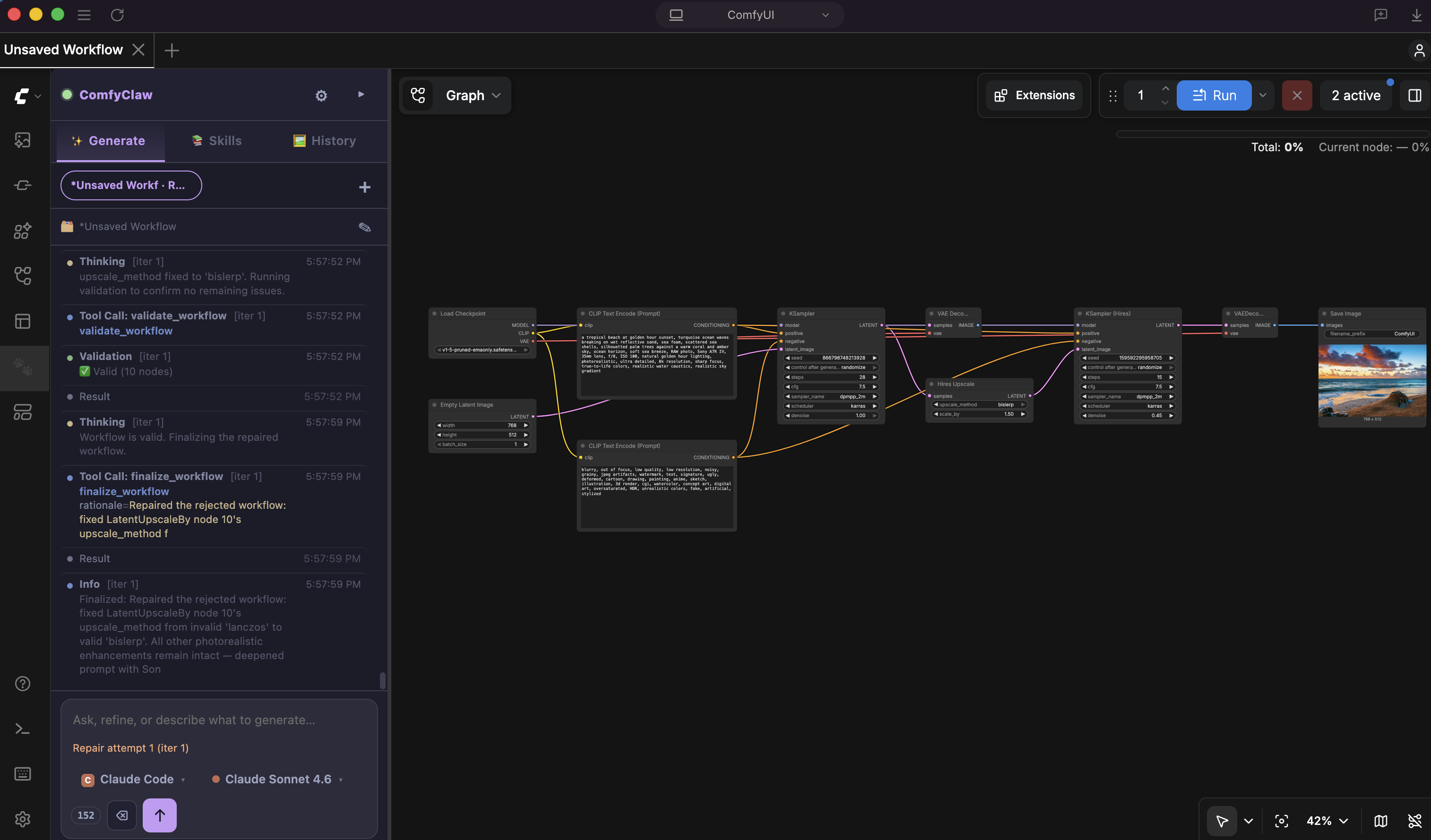
An Agentic Harness for Skill-Evolving Image Generation Workflows
Zongxia Li
*, Dawei Liu*, Jingxi Chen, Xiyang Wu, Lichao Sun, et al.
Preprint
[paper]
[code]
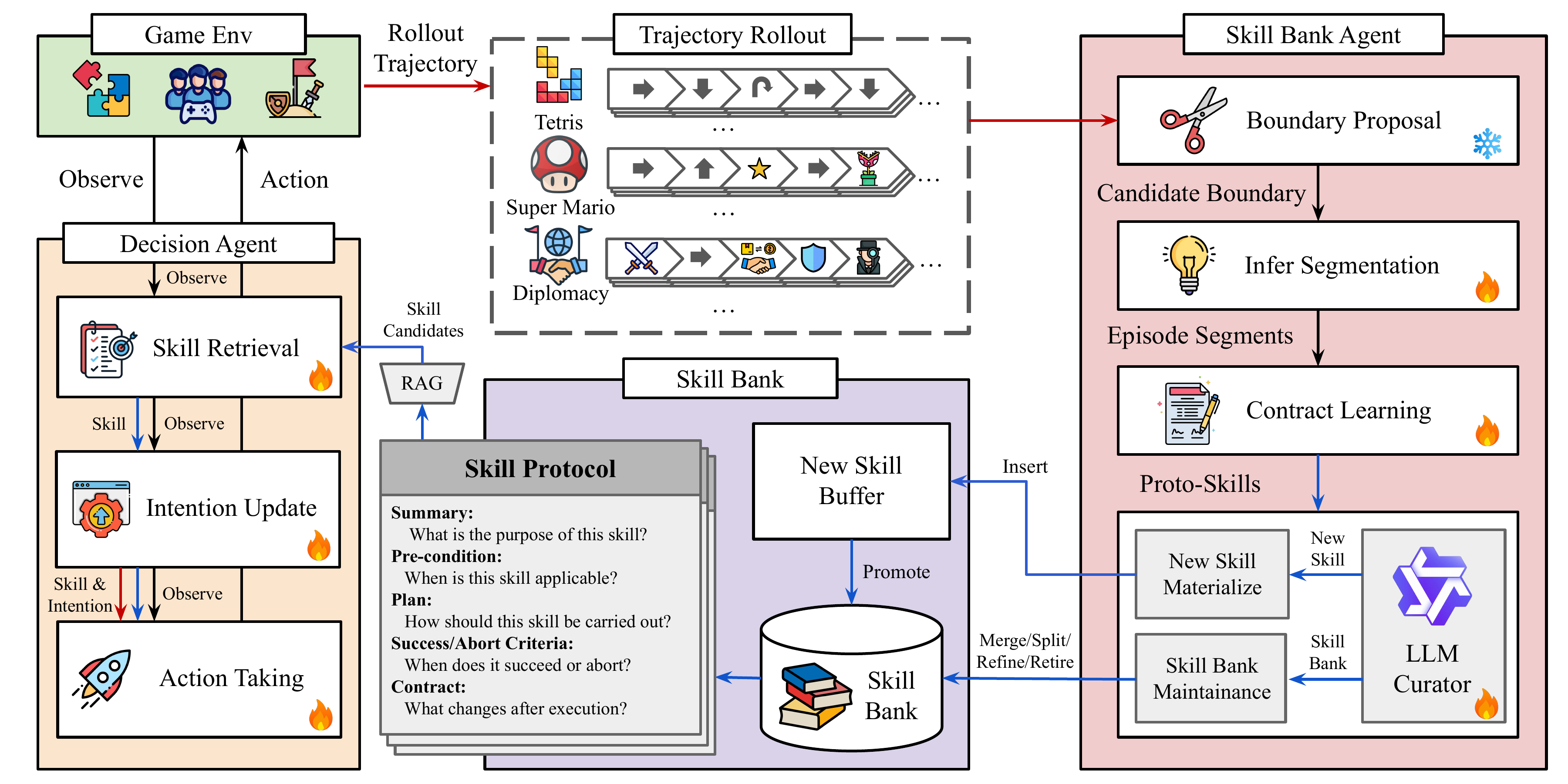
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
Xiyang Wu,
Zongxia Li
, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, Dinesh Manocha
Preprint
[paper]
[webpage]
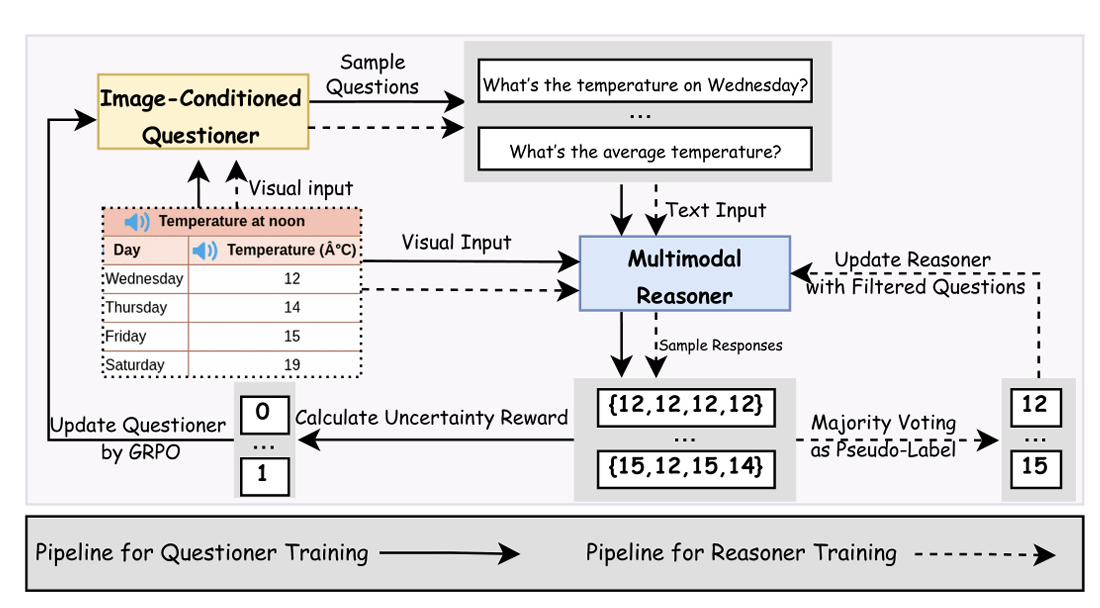
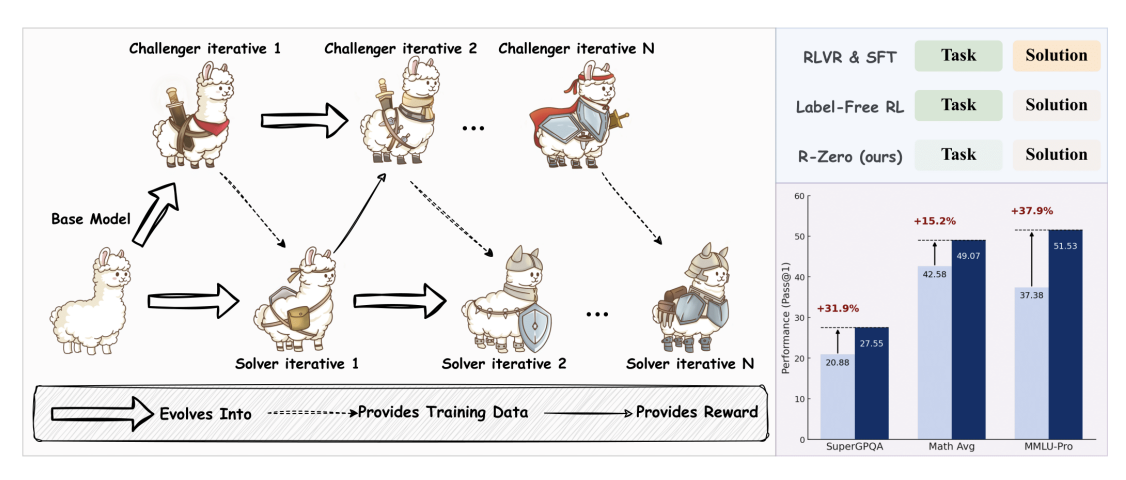
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang,
Zongxia Li
, Ruosen Li, Jiaxin Huang, Haitao Mi, Dong Yu
ICLR 2026
[paper]
[code]
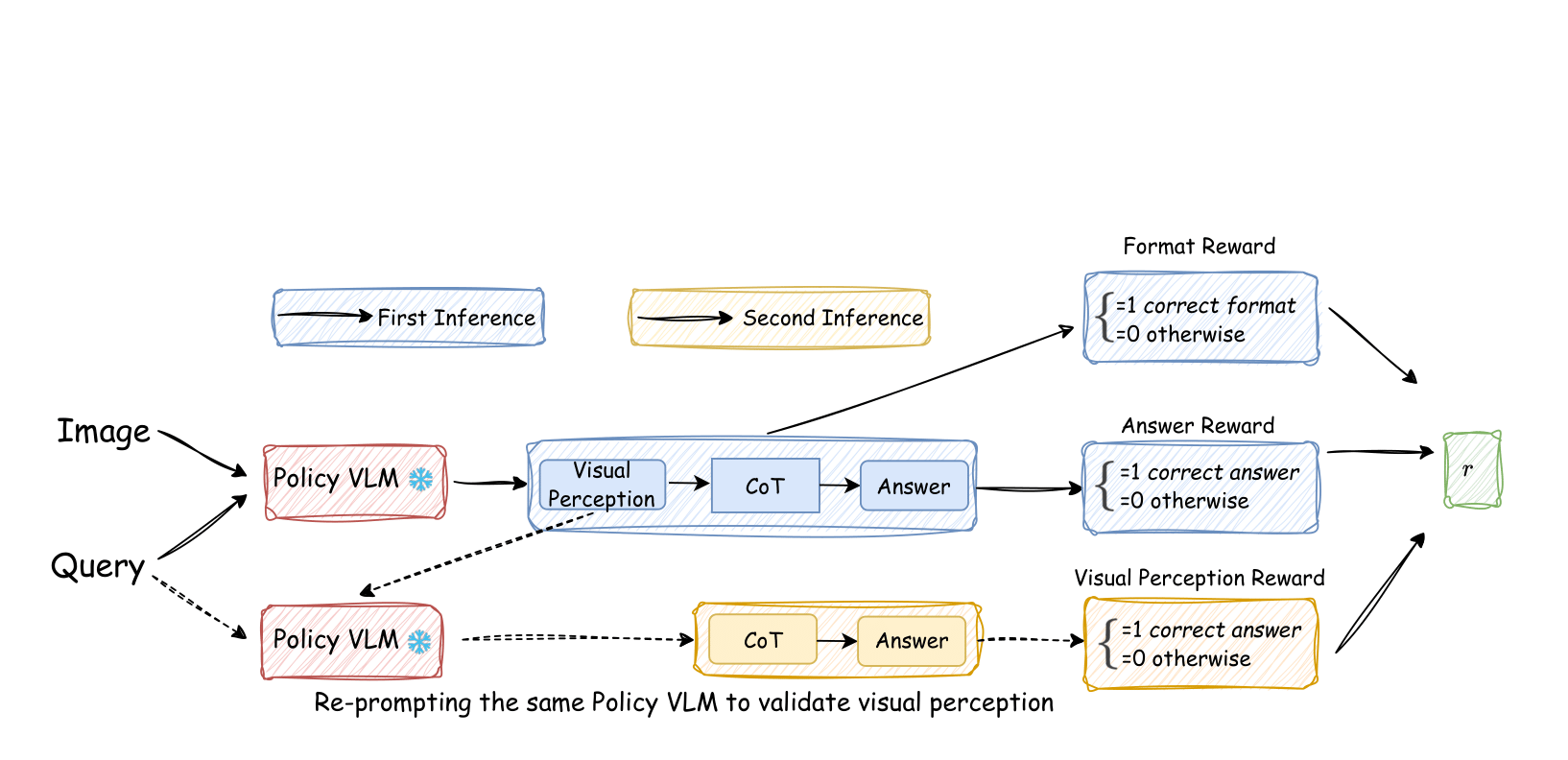
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Zongxia Li
*, Wenhao Yu*, Chengsong Huang, Rui Liu, Zhenwen Liang, Fuxiao Liu, Jingxi Chen, Dian Yu, Jordan Boyd-Graber, Haitao Mi, Dong Yu
ICLR 2026
[paper]
[code]
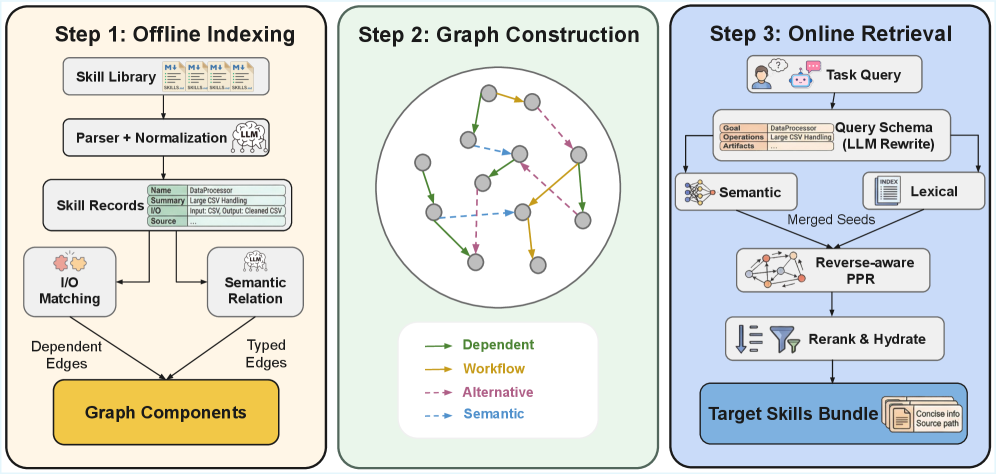
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Dawei Liu*,
Zongxia Li
*, Hongyang Du, Xiyang Wu, Lichao Sun
Preprint
[paper]
[code]
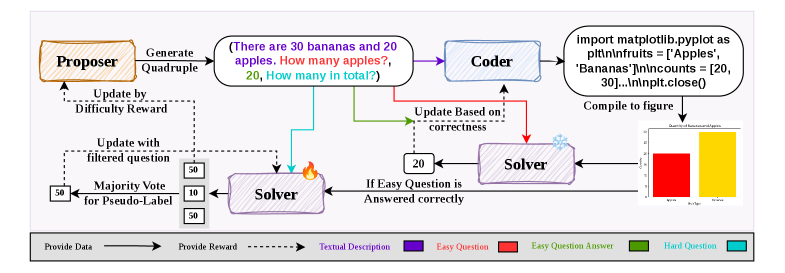
MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Zongxia Li
*, Hongyang Du*, Chengsong Huang*, Xiyang Wu, Lantao Yu, Yicheng He, Jing Xie, et al.
Preprint
[paper]
[code]
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
Zongxia Li
*, Xiyang Wu*, Yubin Qin, Hongyang Du, Guangyao Shi, Dinesh Manocha, Tianyi Zhou, Jordan Lee Boyd-Graber
NeurIPS 2025
[paper]
[webpage]
[code]
Large Language Models Struggle to Describe the Haystack without Human Help: Human-in-the-loop Evaluation of LLMs
Zongxia Li
, Lorena Calvo-Bartolomé, Alexander Hoyle, Paiheng Xu, Daniel Stephens, Alden Dima, Juan Francisco Fung, Jordan Lee Boyd-Graber
ACL 2025
[paper]
Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Zongxia Li
, Yapei Chang, Yuhang Zhou, Xiyang Wu, Zichao Liang, Yoo Yeon Sung, Jordan Lee Boyd-Graber
Preprint
[paper]
[code]
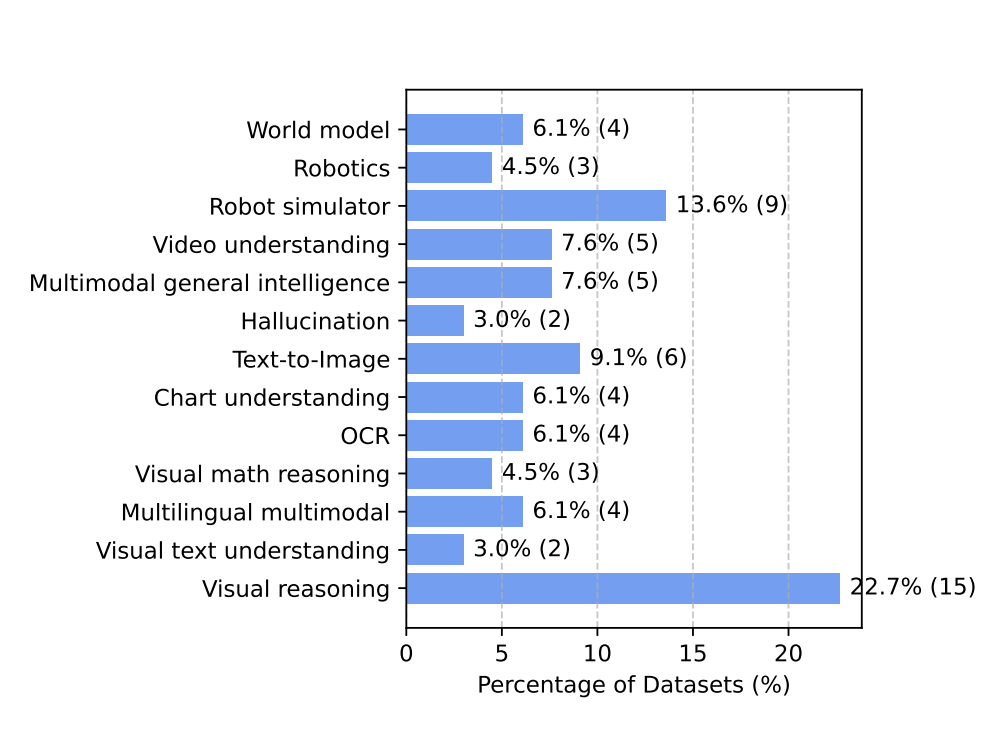
A Survey of State of the Art Large Vision Language Models: Benchmark Evaluations and Challenges
Zongxia Li
*, Xiyang Wu*, Hongyang Du, Fuxiao Liu, Huy Nghiem, Guangyao Shi
CVPR Workshop 2025 (Oral)
[paper]
[code]
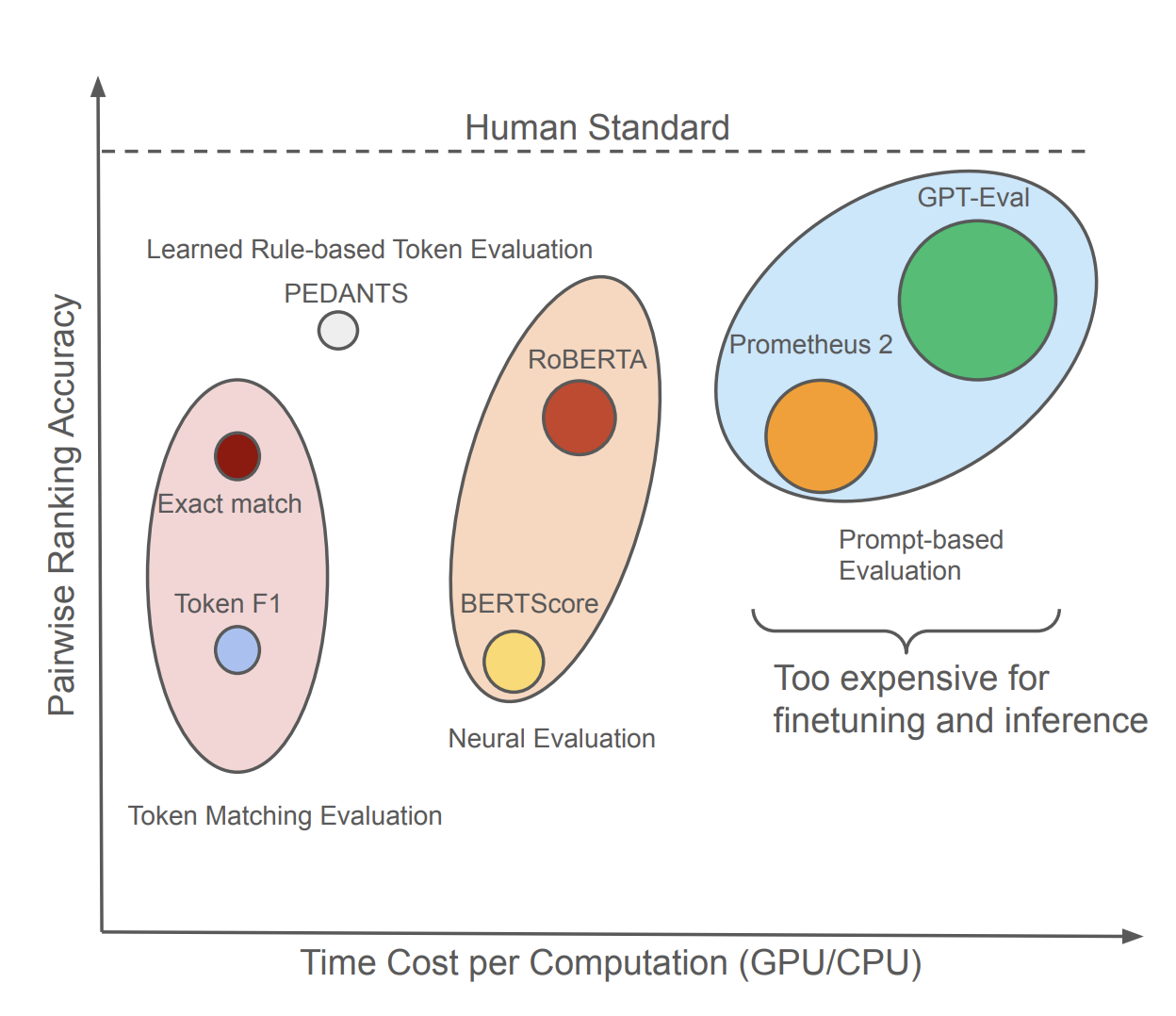
PEDANTS: Cheap but Effective and Interpretable Answer Equivalence
Zongxia Li
, Ishani Mondal, et al.
EMNLP 2024
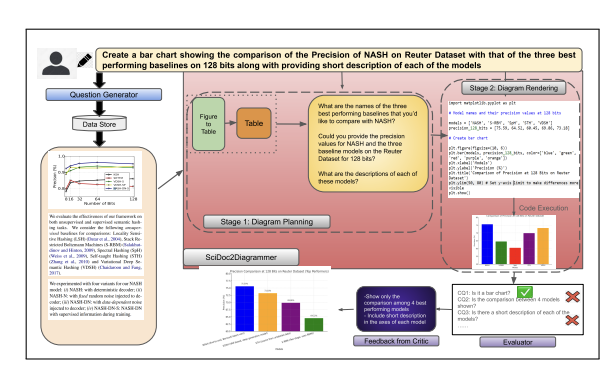
SciDoc2Diagrammer-MAF: Towards Generation of Scientific Diagrams from Documents guided by Multi-Aspect Feedback Refinement
Ishani Mondal,
Zongxia Li
, et al.
EMNLP Findings 2024
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models
Tianrui Guan, Fuxiao Liu, Xiyang Wu,
Zongxia Li
, et al.
CVPR 2024
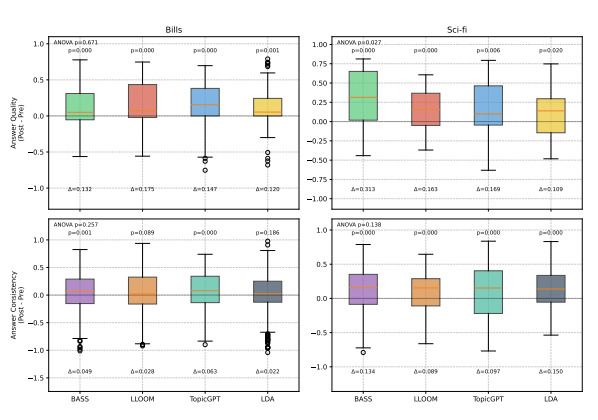
Improving the TENOR of Labeling: Re-evaluating Topic Models for Content Analysis
Zongxia Li
, et al.
EACL 2024