
Sitemap
A list of all the posts and pages found on the site. For you robots out there, there is an XML version available for digesting as well.
Pages
Posts
portfolio
publications
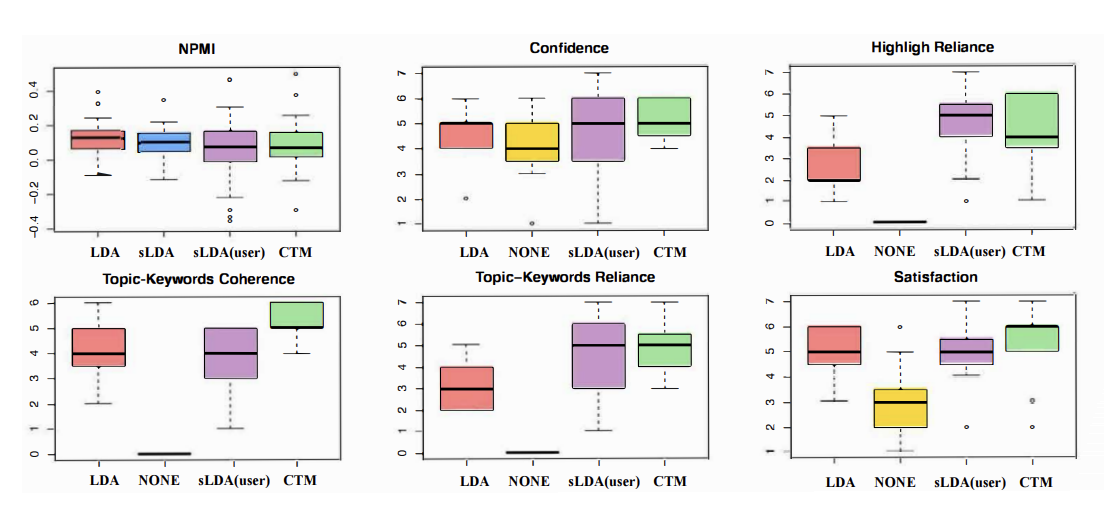
Improving the TENOR of Labeling: Re-evaluating Topic Models for Content Analysis
Published in EACL 2024, 2024
We re-evaluate topic models for content analysis, showing that model choice should be situation-specific depending on the application domain.

HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models
Published in CVPR 2024, 2024
Diagnoses entangled language hallucination and visual illusion in large vision-language models.
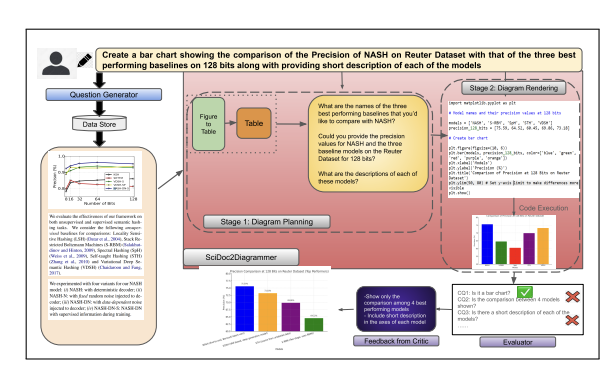
SciDoc2Diagrammer-MAF: Towards Generation of Scientific Diagrams from Documents guided by Multi-Aspect Feedback Refinement
Published in EMNLP Findings 2024, 2024
Generates scientific diagrams from documents using multi-aspect feedback refinement.
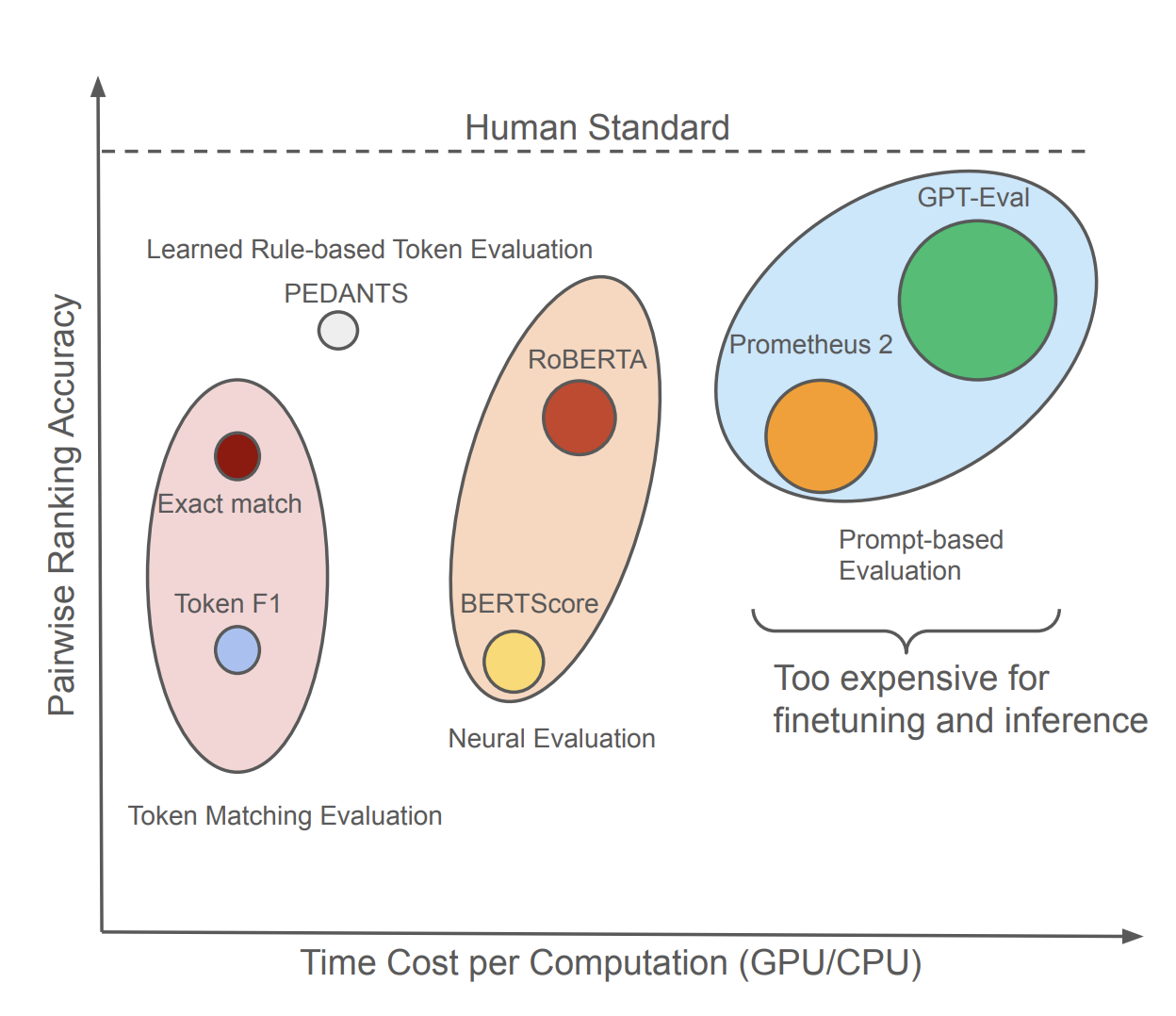
PEDANTS: Cheap but Effective and Interpretable Answer Equivalence
Published in EMNLP 2024, 2024
A cheap, interpretable approach to answer equivalence evaluation that correlates well with human judgments.
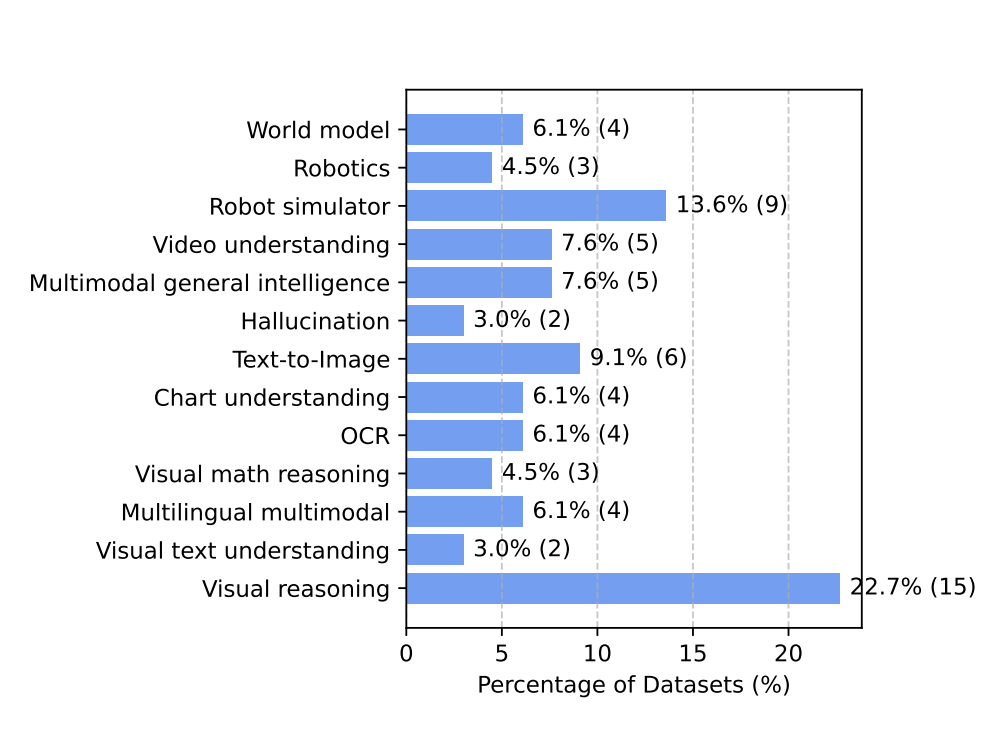
A Survey of State of the Art Large Vision Language Models: Benchmark Evaluations and Challenges
Published in CVPR Workshop 2025 (Oral), 2025
A comprehensive survey of VLMs covering model architectures, alignment methods, benchmarks, and challenges including hallucination, fairness, and safety.

Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Published in Preprint, 2025
PrefBERT scores open-ended long-form generation in GRPO, providing better semantic reward feedback than ROUGE-L and BERTScore.
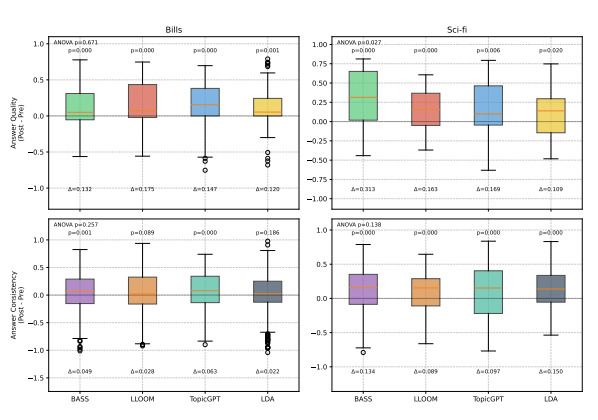
Large Language Models Struggle to Describe the Haystack without Human Help: Human-in-the-loop Evaluation of LLMs
Published in ACL 2025, 2025
We measure knowledge users acquire with topic models, finding that LLM-based methods generate human-readable but overly generic topics for domain-specific data.

VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
Published in NeurIPS 2025, 2025
A benchmark for evaluating and mitigating hallucinations in MLLMs on synthetic videos from Sora, Veo2, and Kling.
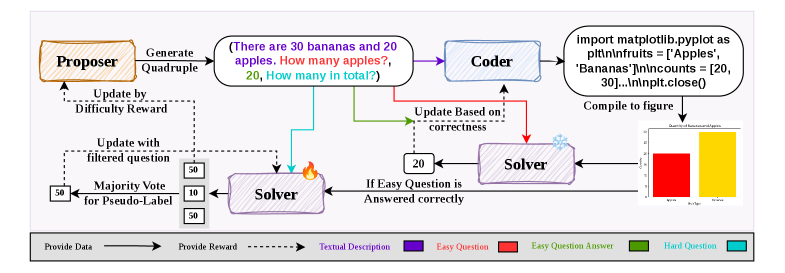
MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Published in Preprint, 2026
The first RL-based framework to achieve zero-data self-evolution for VLM reasoning via a multi-role training framework with a Proposer, Coder, and Solver.
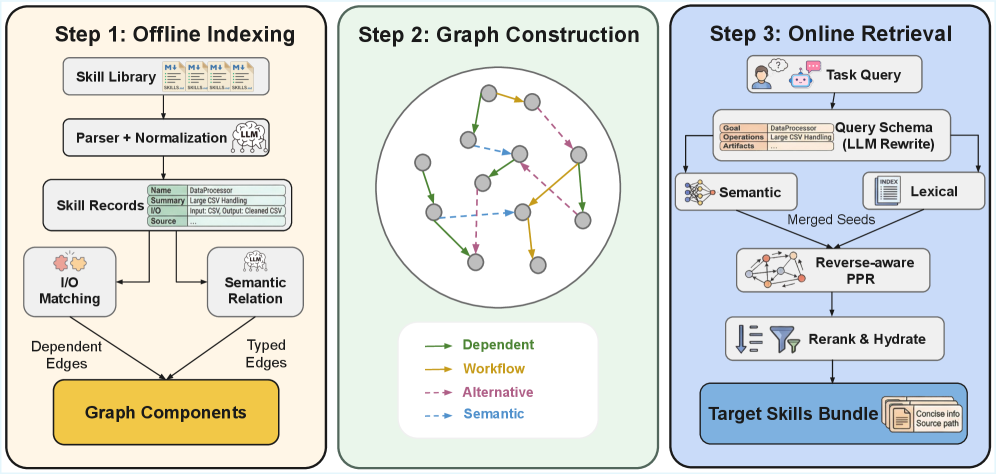
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Published in Preprint, 2026
An inference-time structural retrieval layer that constructs an executable skill graph offline and retrieves dependency-aware skill bundles at inference time.
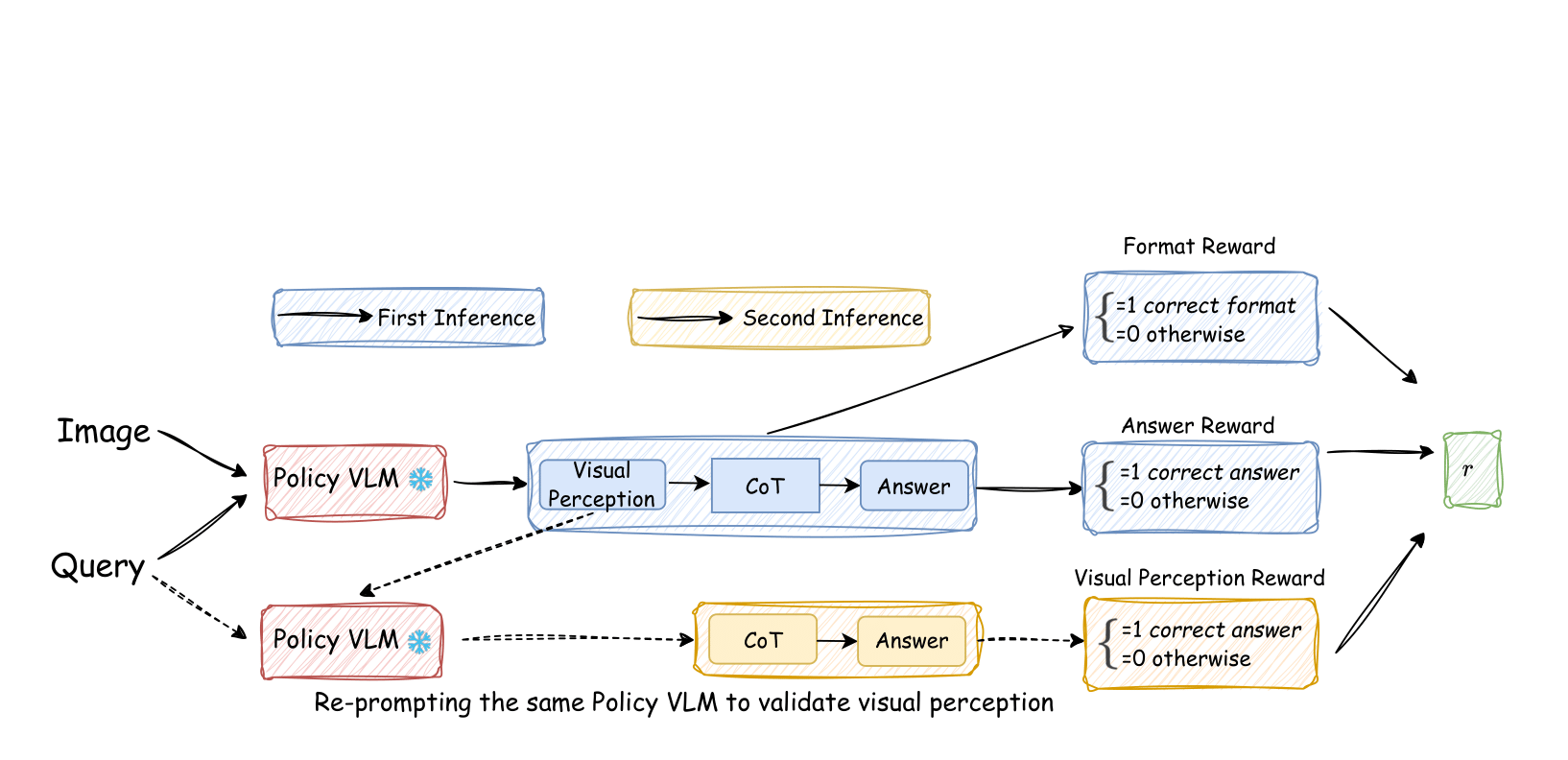
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Published in ICLR 2026, 2026
Vision-SR1 trains VLMs to self-reward by splitting reasoning into visual perception and language reasoning, improving without human labels or external rewards.
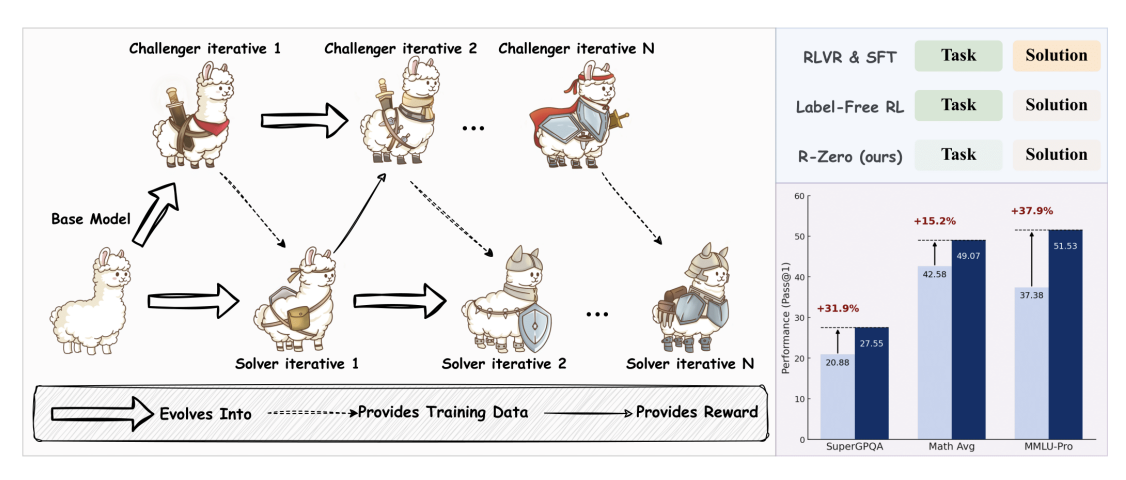
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Published in ICLR 2026, 2026
R-Zero trains LLMs entirely without human-curated data by pitting two copies of the base model against each other in a self-evolving curriculum.
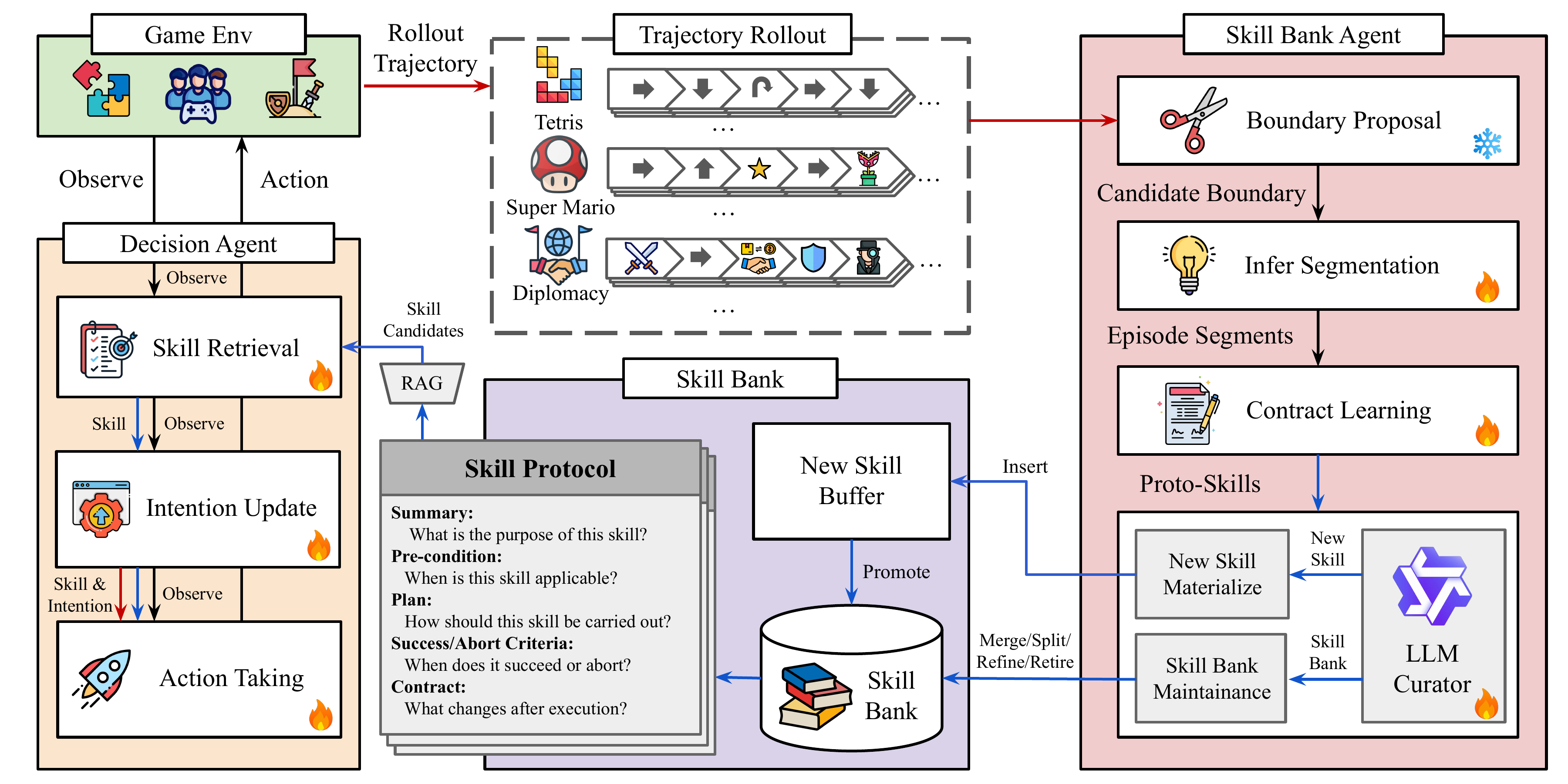
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
Published in Preprint, 2026
COS-PLAY introduces a co-evolution framework where LLM decision agents and skill bank agents mutually improve each other for long-horizon task completion.
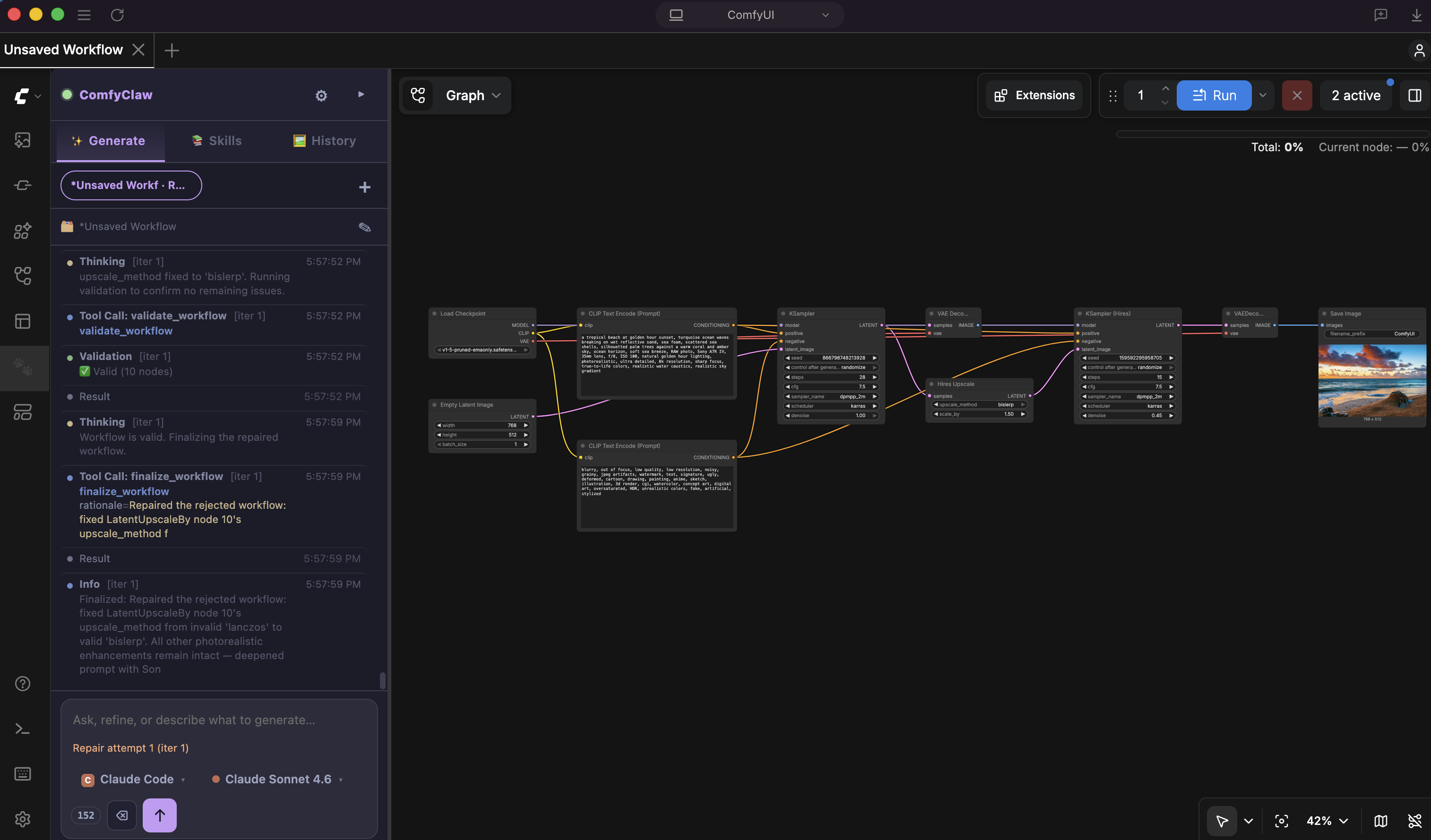
An Agentic Harness for Skill-Evolving Image Generation Workflows
Published in Preprint, 2026
An agentic harness that autonomously develops and refines image generation skills, enabling continuous improvement without manual intervention.

First Frame Is the Place to Go for Video Content Customization
Published in CVPR 2026, 2026
Video models implicitly treat the first frame as a conceptual memory buffer for visual entities, enabling robust video content customization with only 20-50 training examples.
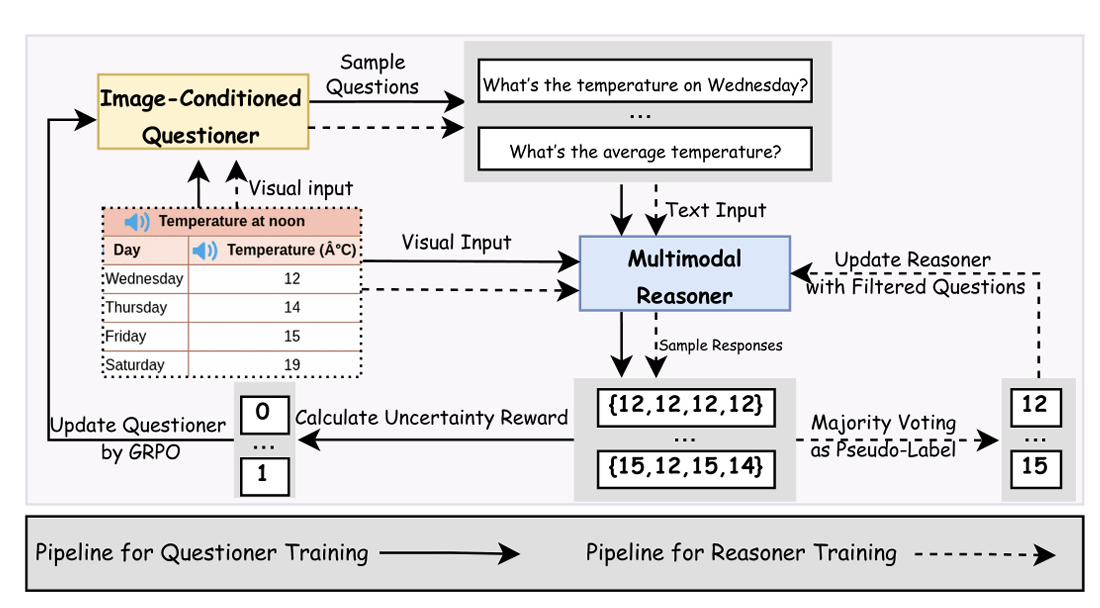
VisPlay: Self-Evolving Vision-Language Models from Images
Published in CVPR 2026, 2026
A self-evolving RL framework that enables VLMs to autonomously improve reasoning abilities from large amounts of unlabeled image data.
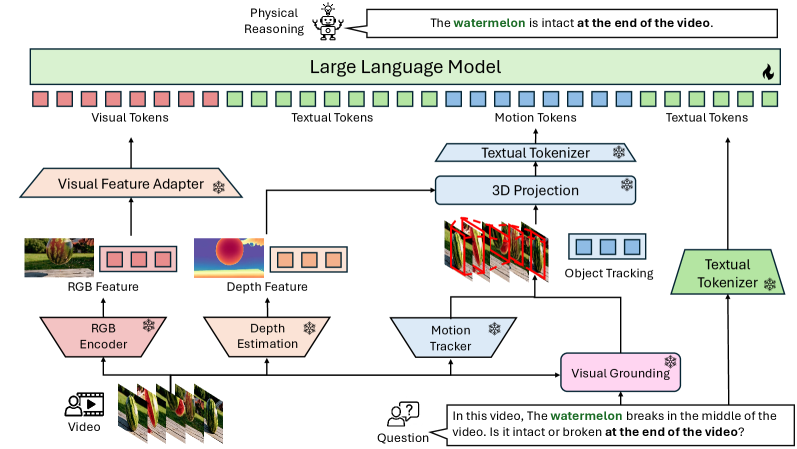
MASS: Motion-Aware Spatial-Temporal Grounding for Physics Reasoning and Comprehension in Vision-Language Models
Published in CVPR 2026, 2026
MASS injects motion-aware spatial-temporal signals into VLMs, improving physics reasoning on a new benchmark of 4,350 real-world and AI-generated videos.
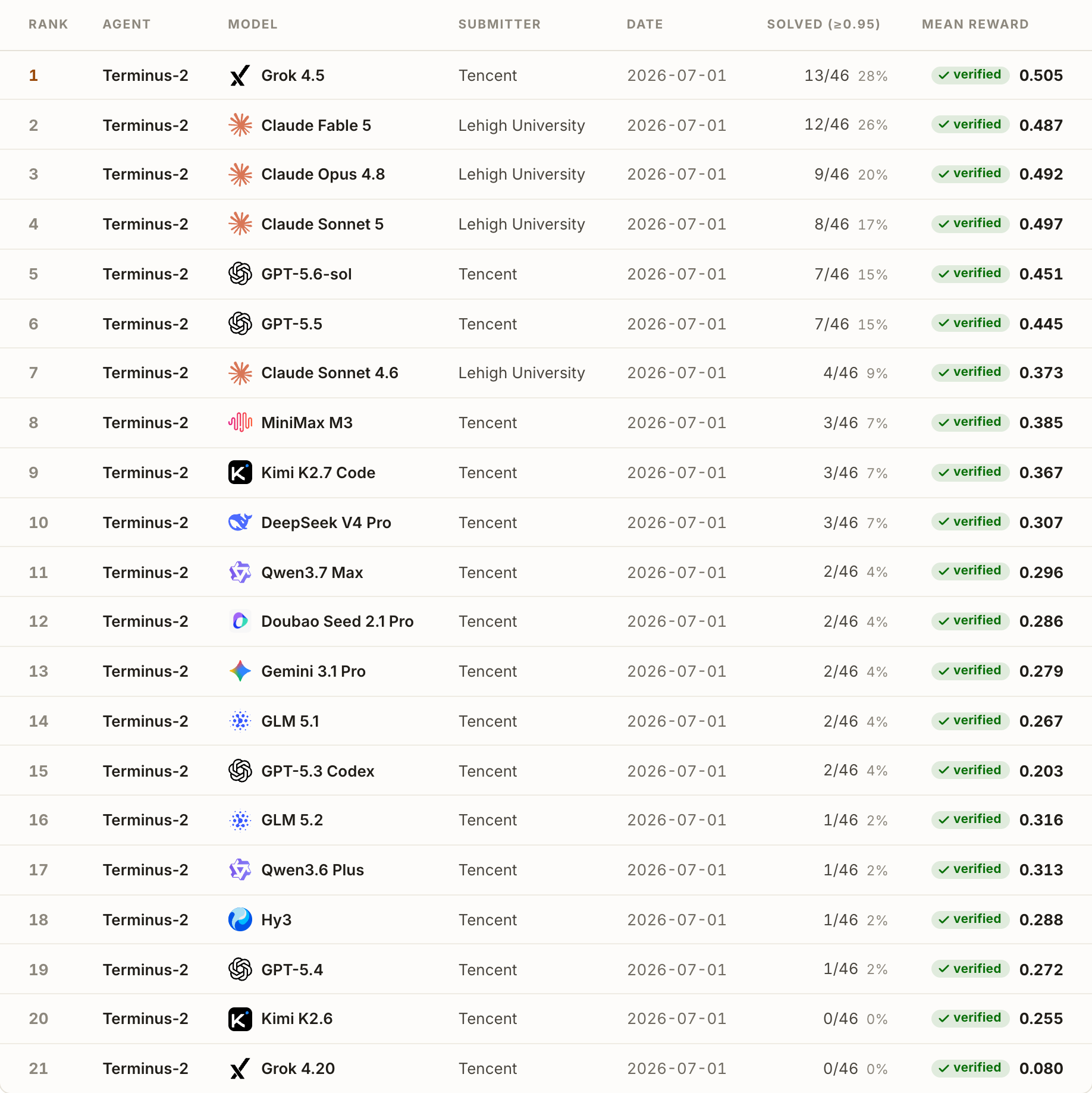
Long-Horizon-Terminal-Bench: Testing the Limits of Agents on Long-Horizon Terminal Tasks with Dense Reward-Based Grading
Published in Preprint, 2026
A benchmark of 46 complex, graded long-horizon terminal tasks across nine domains; the best of 15 tested models reaches only 15.2% success at relaxed thresholds.
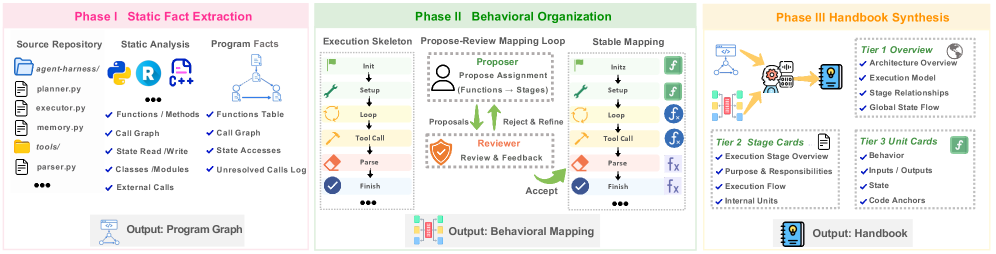
Harness Handbook: Making Evolving Agent Harnesses Readable, Navigable, and Editable
Published in Preprint, 2026
A handbook synthesized via static analysis and LLM-assisted structuring that maps agent-harness behaviors to source code, paired with Behavior-Guided Progressive Disclosure for efficient, localized edits.